「全球及び日本域確率的気候予測データ(d4PDF シリーズ)」を可視化する - 日本域ダウンスケーリングデータを用いて大雨の将来予測を可視化する。
はじめに
「全球及び日本域確率的気候予測データ(d4PDF シリーズ)」は、「大規模アンサンブル気候シミュレーション出力をまとめたデータベースの総称」で、「社会的関心の高い豪雨や台風などの発現頻度が低い顕著な大気現象の将来変化を評価・推定することに重点を置いて設計されたデータベース」です。(気候予測データセット解説書第1章.P1-9より抜粋)
大雨といえば、北海道でも8月はじめにこんなニュースがありました。
将来このような気象が、どのくらいの頻度で発生すると予測されるか?d4PDFデータを用いて可視化してみましょう。
データ入手
20kmの地域気候モデルのデータのうち、北海道が含まれる範囲を切り出してダウンロードします。
気候予測データセット(DS2022)のホームページにアクセス
diasjp.netデータセット紹介→全球及び日本域確率的気候予測データ(d4PDF シリーズ)に進む
日本域ダウンスケーリングをクリック
データ取得/閲覧をクリック
d4PDF_RCM(Subset)タブを選択
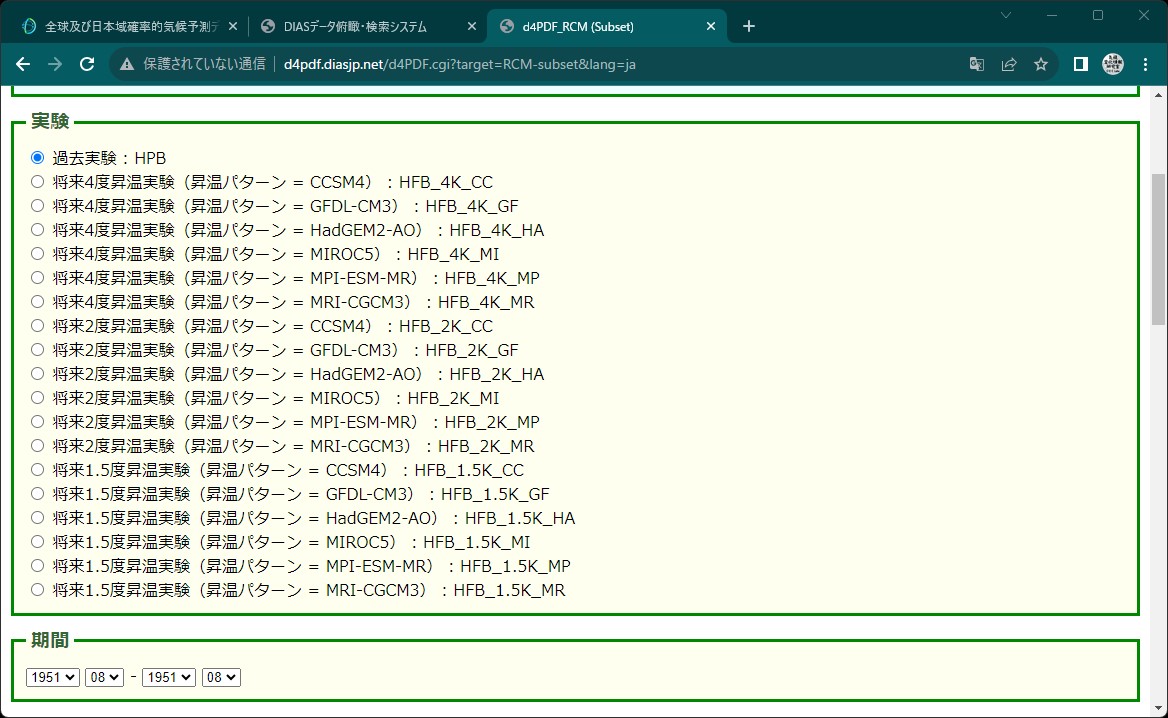
切り出し条件を設定(北海道エリア)
- 実験:過去実験:HPB
- 期間:1951 08 - 1951 08
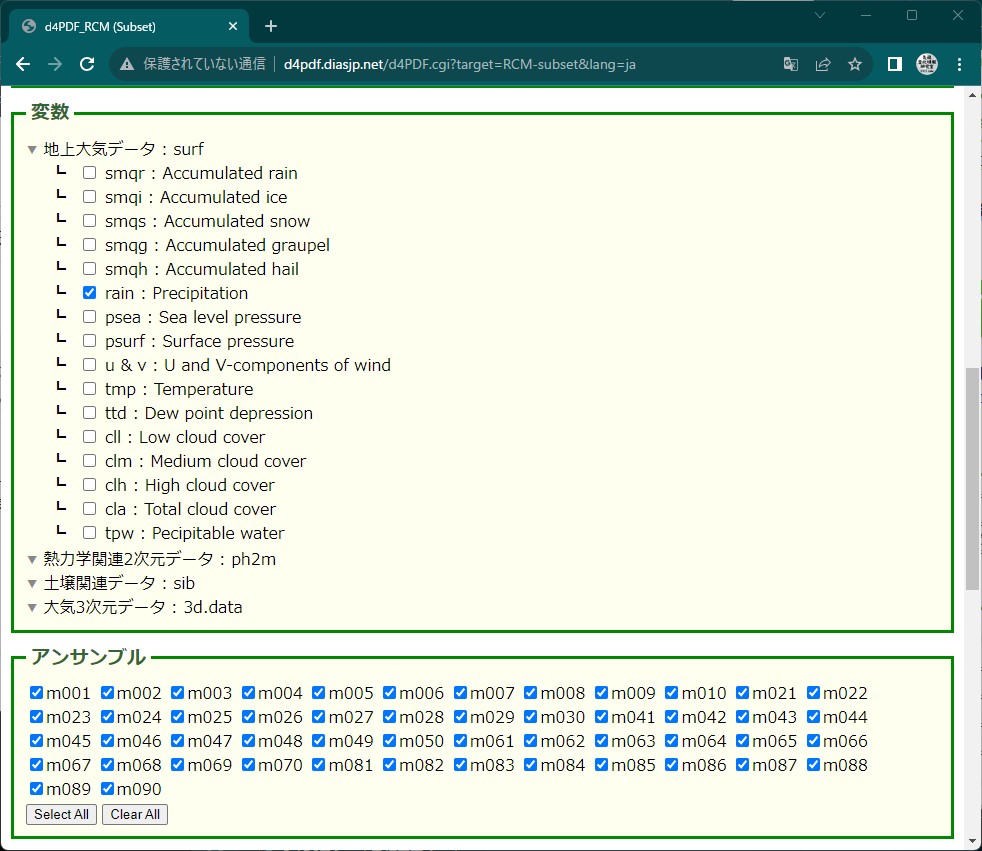
- 変数:地上大気データ:surf → rain:Precipitation
- アンサンブル:Select All
- 領域:Xleft 112, Xright 140, Ybottom 110, Ytop 135
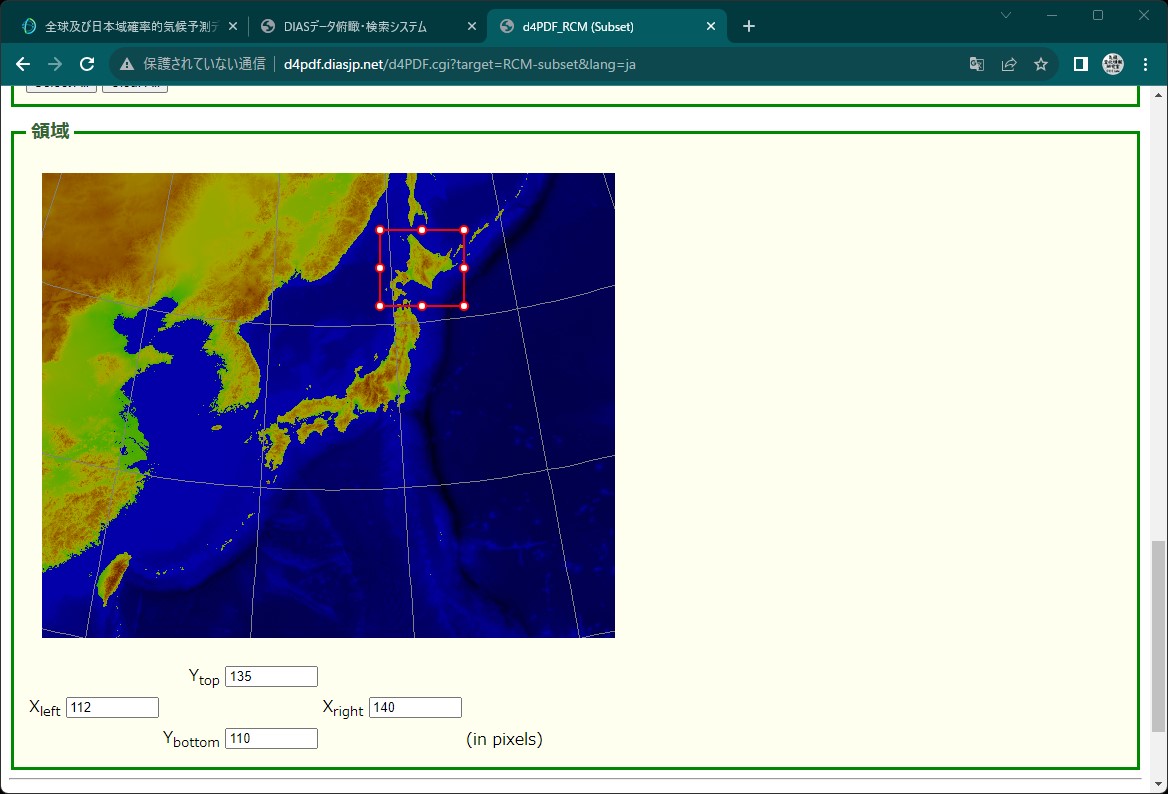
切り出しをクリック

"subset_tar"というファイルがダウンロードされます。
データ切り出しスクリプトの利用
HPBだけでも1951年から2011年まで60年分マウスクリックするのはつらいので、ダウンロードスクリプトを使用します。
スクリプトはページの最後にありますので、ダウンロードしてホームディレクトリに作成した"d4PDF"フォルダに保存し、WSL2コンソールで解凍します。
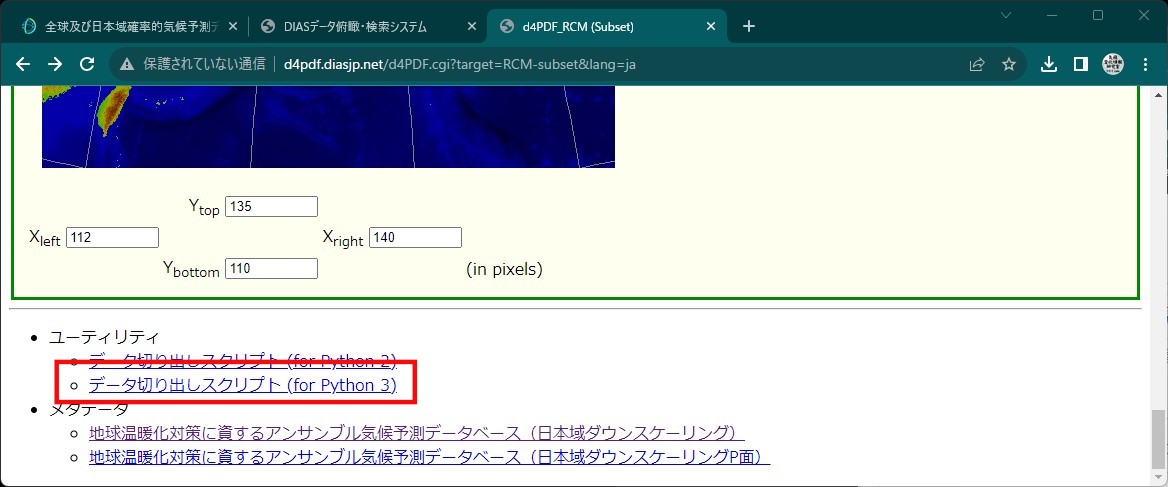
cd /mnt/c/Users/hoge/d4PDF tar -xvf d4pdf-subset-script-3.tgz
先ほどマウスで行った切り出し処理のコマンドはこのようになります。
python3 d4pdf-sb.py -o subset.tar -f 1951-08 -t 1951-08 -X 112,140 -Y 110,135 RCM/HPB/Surf rain
実行時にユーザのホームディレクトリにある.netrcを参照するようなので、作成しておきます。
nano ~/.netrc
DIASのユーザー設定を記入します。
machine d4pdf.diasjp.net
login {DIASのユーザー名}
password {DIASのパスワード}
ファイルのパーミッションを変更しておきます。
chmod og-rw ~/.netrc
Pythonのsubprocessを用いて1年づつ実行します。
# ライブラリのインポート import os import numpy as np import pandas as pd import subprocess os.chdir("/mnt/c/Users/hoge/d4PDF") # HPB切り出し条件の設定 subset_df = pd.DataFrame({"year":np.arange(1951,2012)}) subset_df["output"] = subset_df["year"].map(lambda x: "HPB_{}.tar".format(x)) subset_df["from"] = subset_df["year"].map(lambda x: "{}-08".format(x)) subset_df["to"] = subset_df["from"] for _,hrow in subset_df.iterrows(): cmd = ["python3","d4pdf-sb.py","-o",hrow["output"], "-f",hrow["from"],"-t",hrow["to"],"-X","112,140","-Y","110,135", "RCM/HPB/surf","rain"] subprocess.run(cmd) # HFB_4K_CC切り出し条件の設定 subset_df = pd.DataFrame({"year":np.arange(2051,2111)}) subset_df["output"] = subset_df["year"].map(lambda x: "HFB_4K_CC_{}.tar".format(x)) subset_df["from"] = subset_df["year"].map(lambda x: "{}-08".format(x)) subset_df["to"] = subset_df["from"] # 切り出し実行 for _,hrow in subset_df.iterrows(): cmd = ["python3","d4pdf-sb.py","-o",hrow["output"], "-f",hrow["from"],"-t",hrow["to"],"-X","112,140","-Y","110,135", "RCM/HFB_4K_CC/surf","rain"] subprocess.run(cmd) # 'HFB_4K_GF' 'HFB_4K_HA' 'HFB_4K_MI' 'HFB_4K_MP' 'HFB_4K_MR' も同様にダウンロードします。
tarの解凍
WSL2コンソールから解凍します
cd /mnt/c/Users/hoge/d4PDF find ./ -type f -name "*.tar" | xargs -n 1 tar xf
「平年8月1か月分の総雨量」を求める
過去実験(HPB)のすべての年、すべてのアンサンブルについて8月の総雨量を計算し、その平均値を「平年8月1か月分の総雨量」とします。
ここでは、時間雨量0.5㎜未満を無降水として扱いました。
# ライブラリのインポート import os import pathlib import numpy as np import pandas as pd os.chdir("/mnt/c/Users/hoge/d4PDF") # 処理ファイルのリストを作成する files_df = pd.DataFrame({"f_path":list(pathlib.Path("/mnt/c/Users/hoge/d4PDF/d4PDF_RCM/HPB").glob("**/*rain_subset.dat"))}) # 月総雨量を収納する配列を作成しておく monthly_arr = np.zeros((files_df.shape[0],26,29)) # 1ファイルずつ処理 for ind,hrow in files_df.iterrows(): # バイナリファイルを読み込み dvec = np.fromfile(hrow["f_path"],dtype='>f4') # 4次元の配列に変換 darr = dvec.reshape(744,26,29) # 総雨量を計算して、空の配列に格納 monthly_arr[ind,:,:] = darr.sum(axis=0) # 平均年値を計算して保存しておく climate_normal = monthly_arr.mean(axis=0) np.save("./aug_rain/climate_normal_sumrain.npy",climate_normal)
結果を図にしてみると、こんな感じです。
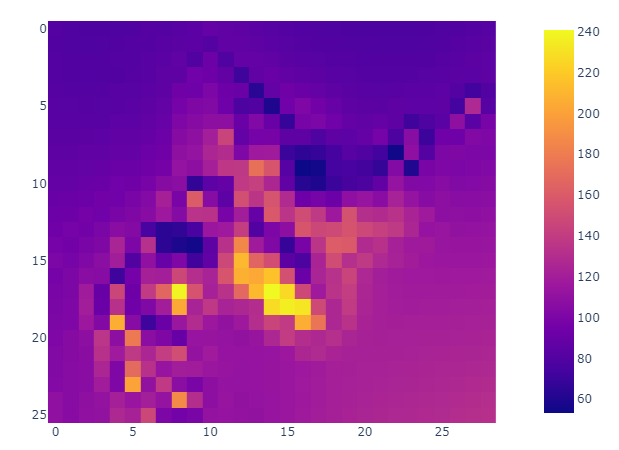
メッシュ平年値図と比べて、値の範囲的には一致しているようです。
https://www.data.jma.go.jp/obd/stats/etrn/view/atlas/docs2020/png_large/prec/precipitation_08.png

降雨イベントの検出と統計処理
雨の降り始めから降り終わりまでを1つの降雨イベント(ひと雨)とし、降り始めからの積算雨量が8月の総雨量の平年値を超える回数を計算します。ここでは、24時間以上の無降水が継続したときを降雨イベントの区切りとしました。
# ライブラリのインポート import os import pathlib import numpy as np import pandas as pd os.chdir("/mnt/c/Users/hoge/d4PDF") def res_counts_total_storm_prcip(ts_vec,threshold): #24hr雨量の計算 mvsum_24hr_vec = np.concatenate( [np.zeros(23), np.convolve(ts_vec,np.ones(24),mode="valid")] ) #降雨イベントのインデックスを作成 pr_event_no =np.concatenate( [np.zeros(1), (np.convolve(mvsum_24hr_vec == 0,(-1,1),mode="valid") == 1).cumsum()] ).astype(int) #イベントごとの積算雨量を計算 TP_vec = np.bincount(pr_event_no, weights=ts_vec) #閾値を超える回数を集計して返す return((TP_vec > threshold).sum()) # 8月の総雨量の平年値を読み込んでおく climate_normal = np.load("./aug_rain/climate_normal_sumrain.npy") # ファイルリストの作成 files_df = pd.DataFrame({"f_path":list(pathlib.Path("./d4PDF_RCM/").glob("**/*rain_subset.dat"))}) files_df["f_name"] = files_df["f_path"].map(lambda x:x.name) files_df["ens_name"] = files_df["f_name"].str.extract("surf_(.*)_\d{6}_rain.*") # アンサンブルごとに超過回数を計算する for e_name,hgrp in files_df.groupby("ens_name"): # 返り値の入れ物を作成 counts_arr = np.zeros((hgrp.shape[0],26,29)) # インデックスをリセット hgrp = hgrp.reset_index(drop=True) for Tind,hrow in hgrp.iterrows(): # ファイルの読み込み dvec = np.fromfile(hrow["f_path"],dtype=">f4") dvec = dvec.astype(float) # 4次元の配列に変換 darr = dvec.reshape(744,26,29) # 時間雨量0.5㎜を無降水に darr[darr<0.5] = 0 # 次元を入れ替えて、Y,X,timeにする darr = darr.transpose(1,2,0) # 格子点ごとに処理 for Yind,X_darr in enumerate(darr): for Xind,ts_vec in enumerate(X_darr): thresh = climate_normal[Yind,Xind] counts_arr[Tind,Yind,Xind] = res_counts_total_storm_prcip(ts_vec,thresh) # npy形式で保存 np.save("./aug_rain/counts_over_threshold_rain_total_storm_prec_{}.npy".format(e_name),counts_arr)
大雨の発生確率の計算
「降り始めからの積算雨量が閾値を超えるような降雨イベント」が発生する回数はポアソン分布に従うと仮定し、年に1回以上発生する確率を計算します。
# ライブラリ呼び出し import os import pathlib import numpy as np import pandas as pd from osgeo import gdal, gdalconst, gdal_array from osgeo import osr from scipy.stats import poisson # 地理座標系のパラメータを設定 ul_x = -1930000.1287495417 + 112*20000 ul_y = 5833346.794147097 - (155-135-1)*20000 x_res = 20000 y_res = -20000 x_size = 29 y_size = 26 outRasterSRS = osr.SpatialReference() outRasterSRS.ImportFromProj4( "+proj=lcc +lat_1=30.0 +lat_2=60.0 +lon_0=135. +lat_0=0 +x_0=0 +y_0=0 +a=6371000 +b=6371000 +units=m +no_defs") # ファイルリストの作成 files_df = pd.DataFrame({"f_path":list(pathlib.Path("./aug_rain").glob("counts*.npy"))}) files_df["f_name"] = files_df["f_path"].map(lambda x: x.name) files_df["exper"] = files_df["f_name"].str.extract(".*_prec_([A-Z]*)_.*") for exper,hgrp in files_df.groupby("exper"): # 発生回数の平均を計算 sum_arr = np.zeros((26,29)) sum_counts = 0 for _,hrow in hgrp.iterrows(): counts_arr = np.load(hrow["f_path"]) counts_arr[counts_arr > 1] = 1 sum_arr += counts_arr.sum(axis=0) sum_counts += counts_arr.shape[0] lambda_arr = sum_arr/sum_counts # 1回以上発生する確率 PO_arr = np.vectorize(lambda x: 1-poisson.cdf(0,x))(lambda_arr) # geotiffに保存 name = "Probability_occurrence_heavy_rain{}.gtiff".format(exper) output = gdal.GetDriverByName('GTiff').Create(name,x_size,y_size,1,gdal.GDT_Float64) output.SetProjection(outRasterSRS.ExportToWkt()) output.SetGeoTransform((ul_x, x_res, 0, ul_y, 0, y_res)) outband = output.GetRasterBand(1) outband.WriteArray(PO_arr[::-1,:].astype("float64")) outband.FlushCache() output = None
QGISに読み込む
「レイヤ」→「レイヤを追加」→「ラスタレイヤを追加」
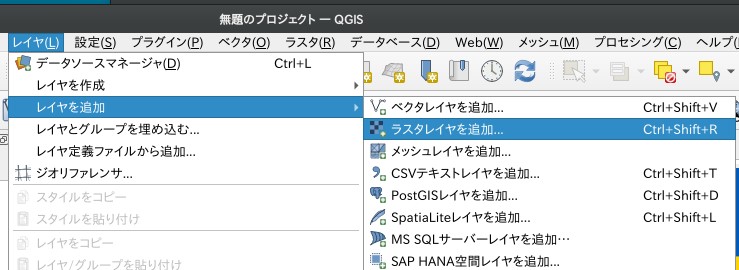
ソース:ラスタデータセットに”Probability_occurrence_heavy_rainHPB.gtiff”を指定して「追加」
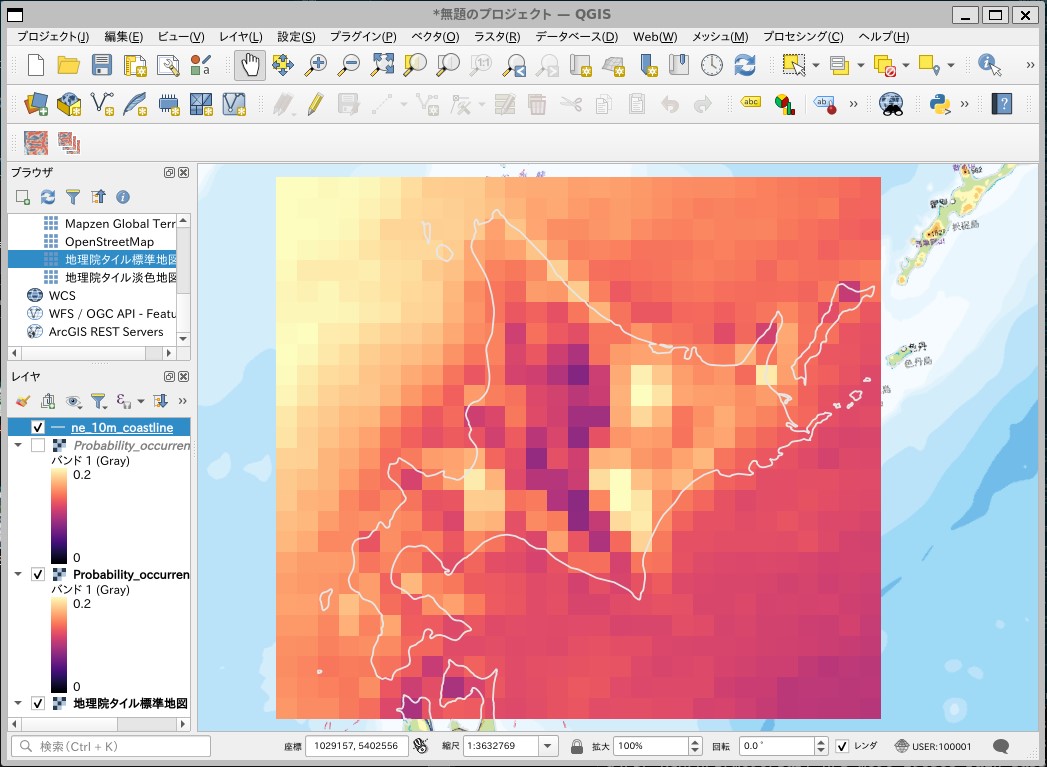
過去実験:HPBにおける「降り始めからの積算雨量が閾値を超えるような降雨イベント」が発生する確率のマップが表示されます。
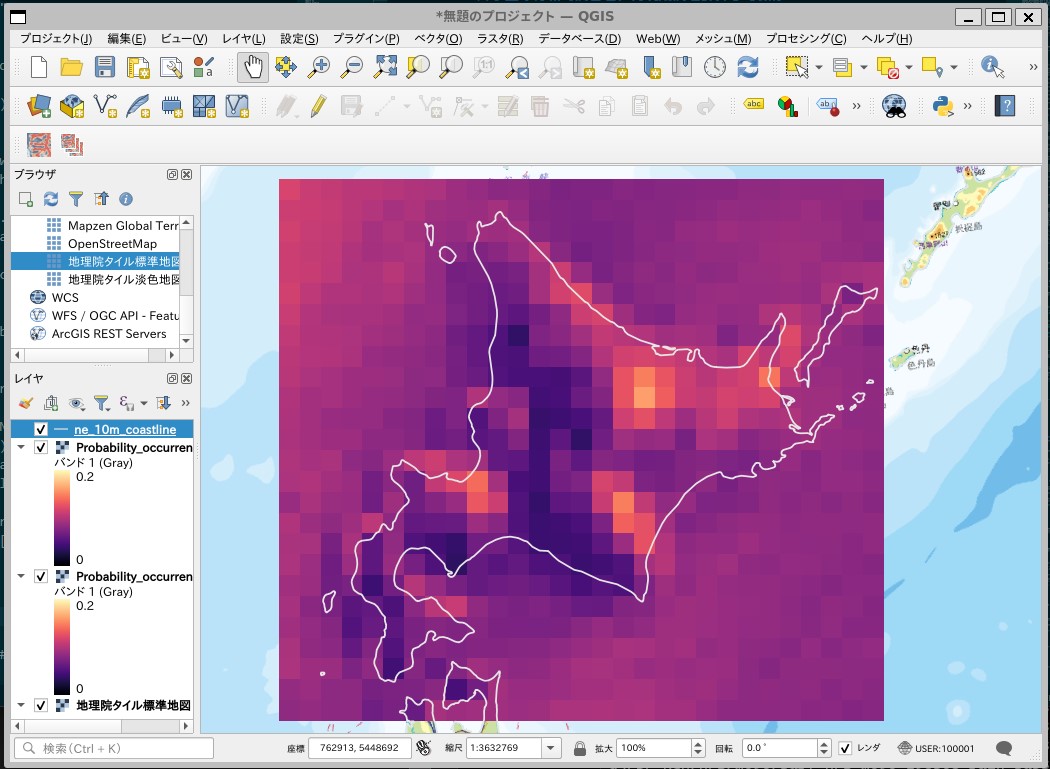
将来4度昇温実験:HFBのマップ
変化率の計算
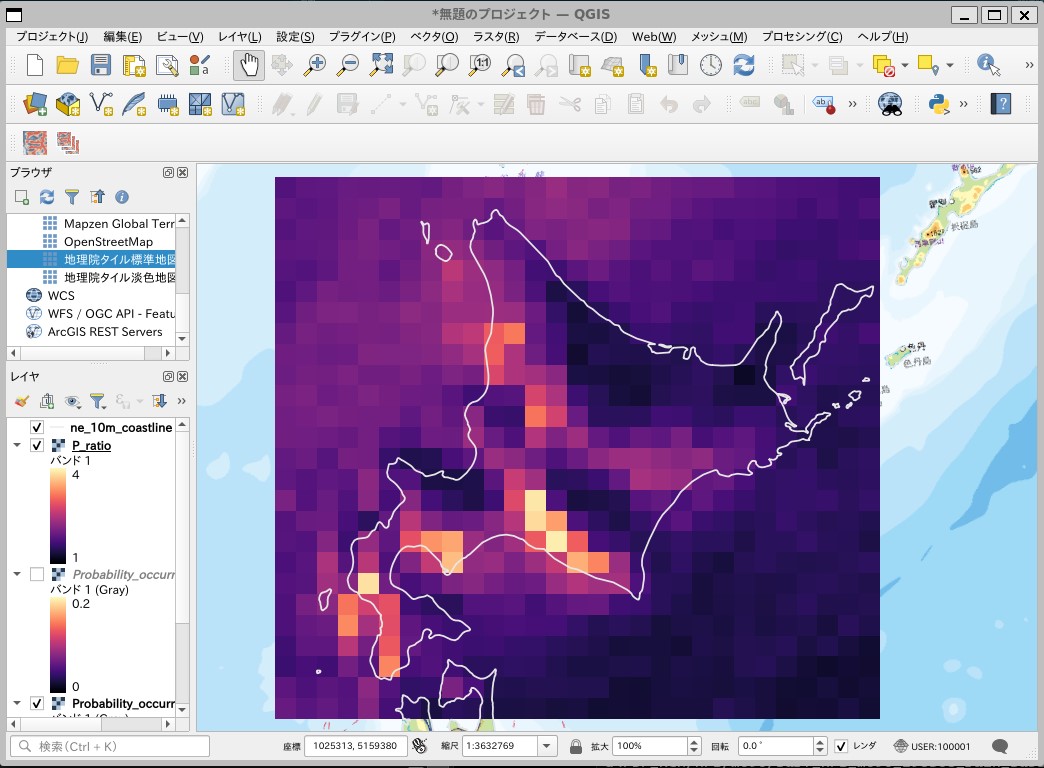
QGISのラスタ計算機を使えば、過去実験と将来4度昇温実験における大雨発生確率の変化倍率を計算できます。
「ラスタ」→「ラスタ計算機」
計算条件を設定
- ディスクに書き込まないオンザフライ・ラスタを作成にチェック
- レイヤ名:HPB_HFB_ratio
- 式:”Probability_occurence_heavy_rainHFB@1"/”Probability_occurence_heavy_rainHPB@1"

変化倍率のマップが計算されます。
と、この記事を書いていたらこんなニュースが。
- d4PDFは領域版でもメッシュ間隔が20kmであるため、狭い範囲に短時間に多量の雨をもたらす線状降水帯や、複雑な地形の影響を受けた大雨を再現することはできませんでした。
- 今回実施した5kmメッシュ(水平格子間隔)のシミュレーションは、d4PDFの20kmメッシュのシミュレーションに比べて、発生頻度の低い大雨の再現性が向上し線状降水帯の検出も可能とな りました。
- 本データセットはデータ統合・解析システム(DIAS)を通じて公開する予定です。
とのことですので、公開を待ちたいと思います。
「全球及び日本域確率的気候予測データ(d4PDF シリーズ)」の 日本域ダウンスケーリングデータを用いて大雨の将来予測を可視化する方法を紹介しました。試してみてくださいね~。
※本記事では、文部科学省による複数の学術研究プログラム(「創生」、「統合」、SI-CAT、DIAS)間連携および地球シミュレータにより作成された d4PDF を使用させていただきました。