気候変動が進んだ将来、「かんしょ」の生産はどのように変化するか? ―その2 10a当たり収量の変化予測―
はじめに
前回は、「かんしょ」の10a当たり収量について平均気温のみを説明変数にした単純な予測モデルを作成しました。
気候変動が進んだ将来、「かんしょ」の10a当たり収量がどのくらい変化すると予測されるか?日本域150年連続実験データを予測モデルに当てはめ、推定してみましょう。
気候予測データの入手
前回作成した予測モデルでは、「かんしょ」の栽培期間の4月〜10月の平均気温を説明変数としています。そこで、以下の記事の手順に従い、RCP8.5シナリオの4月〜10月のデータを入手します。
データを解凍する
# ユーザホームディレクトリにONEFIFTYフォルダを作成し、 # ダウンロードした”data***.tgz”を移動しておく。 cd /mnt/c/Users/hoge/ONEFIFTY/ find ./ -type f -name "*.tgz" | xargs -n 1 tar zxf
次のディレクトリにデータが解凍されます。
C:\Users\hoge\ONEFIFTY\dias\data\GCM60_NHRCM20_150yr_TOUGOU\NHRCM20\RCP8.5
グリッドマスクの作成
150年連続実験データでは、おおよそ110°E〜158°E、20°N〜50°Nの範囲に幅191、高さ155のグリッドが設定されています。このうち日本の陸地が半分以上を占めるグリッドを特定し、マスクを作成します。
import pandas as pd import numpy as np import geopandas as gpd import pathlib from shapely.geometry import Polygon import xarray as xr import rioxarray import arviz import pickle import plotly.graph_objects as go # 陸域データを読み込み # d4PDF日本域ダウンスケーリングデータの海陸比データを利用する # https://qiita.com/c-c-i_labo/items/ab8c381a4373863b59c8 # 海陸比データの読み込み sl_gtif = rioxarray.open_rasterio("/mnt/c/Users/hoge/d4PDF_RCM/topo_essp20_sl.gtiff") sl_df = sl_gtif.to_dataframe(name="sl") sl_df = sl_df.reset_index() sl_df.index.name="gid" # 日本の陸地が半分以上を占めるグリッドを特定 sl_df = sl_df.loc[sl_df["sl"] > 0.5] # GeoDataFrameに変換 poly_geoms = [Polygon([(x-10000,y-10000),(x-10000,y+10000),(x+10000,y+10000),(x+10000,y-10000),(x-10000,y-10000)]) for x,y in zip(sl_df["x"],sl_df["y"])] sl_gdf = gpd.GeoDataFrame(sl_df,geometry=poly_geoms) sl_gdf = sl_gdf.set_crs("+proj=lcc +lat_1=30.0 +lat_2=60.0 +lon_0=135. +lat_0=0 +x_0=0 +y_0=0 +a=6371000 +b=6371000 +units=m +no_defs") # 都道府県の区域データと結合 # 国土数値情報 行政区域データ # https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-N03-2024.html prefec_gdf = gpd.read_file("/mnt/c/Users/hoge/GIS/行政区域データ/N03-20240101_GML.zip") prefec_gdf["prefec_name"] = prefec_gdf["N03_001"] + prefec_gdf["N03_002"].fillna('') prefec_gdf = prefec_gdf.dissolve("prefec_name") sl_gdf = sl_gdf.to_crs("6668").sjoin(prefec_gdf) # 陸域マスクを作成 mask_arr = np.ones(155*191) * -999 mask_arr[sl_gdf["gid"].values] = sl_gdf["gid"].values mask_arr = mask_arr.reshape((155,191))
予測データの切り出し
陸域マスクを使って日本域150年連続実験データを切り出します。
# girbファイルのリストを作成 fdf = pd.DataFrame({"f_path":list(pathlib.Path("/home/kazuh/dataset/ONEFIFTY").glob("**/*.grib"))}) fdf["f_mame"] = fdf["f_path"].map(lambda x: x.name) fdf["group"] = fdf["f_mame"].str.extract("(.{4})_.*") fdf["year"] = fdf["f_mame"].str.extract(".*_(\d{4})\d{2}.grib").astype(int) fdf["month"] = fdf["f_mame"].str.extract(".*_\d{4}(\d{2}).grib").astype(int) fdf = fdf.sort_values(["group","year","month"]) fdf = fdf.reset_index(drop=True) surf_df = fdf.loc[fdf["group"]=="surf"] # 地表気温データをマスクで切り出して月平均を計算 Tmean_month_df = pd.DataFrame(index=[]) for idx,hrow in surf_df.iterrows(): ds = xr.open_dataset(hrow["f_path"], engine="cfgrib") Tmean_month_df = pd.concat([Tmean_month_df, pd.DataFrame({"year":hrow["year"], "mnonth":hrow["month"], "gid":mask_arr[mask_arr!=-999], "Tmean":ds["t"].data[:,::-1,:][:,mask_arr!=-999].mean(axis=0) })]) Tmean_month_df["Tmean"] -= 273.15 # 年平均を計算 Tmean_year_df = Tmean_month_df.groupby(["gid","year"])["Tmean"].agg(["mean","min","max"]) Tmean_year_df = Tmean_year_df.reset_index()
潜在的収量の変化予測
前回作成したモデルを使って潜在的な10a当たり収量の変化を予測してみます。
# サンプリング結果の読み込み with open("model_result.pkl","rb") as f: idata = pickle.load(f) # 切片、傾きの平均値を計算 slope = np.atleast_1d(idata.posterior["slope"].mean().data)[0] intercept = np.atleast_1d(idata.posterior["Intercept"].mean().data)[0] # 潜在的収量を計算 Tmean_year_df["y_pred"] = Tmean_year_df["mean"]*slope+intercept # 1980~1999年の平均を計算 y_pred_1990s = Tmean_year_df.loc[(Tmean_year_df["year"] >= 1980) & (Tmean_year_df["year"] <= 1999),["gid","y_pred"]].groupby("gid")["y_pred"].mean() # 2030~2049年における収量増加率を計算 y_pred_2040s = Tmean_year_df.loc[(Tmean_year_df["year"] >= 2030) & (Tmean_year_df["year"] <= 2049),["gid","y_pred"]].groupby("gid")["y_pred"].mean() inc_rate_2040s = y_pred_2040s/y_pred_1990s inc_rate_map_2040s = np.empty(191*155) inc_rate_map_2040s[:] = np.nan inc_rate_map_2040s[inc_rate_2040s.index.astype(int).values] = inc_rate_2040s.values inc_rate_map_2040s = inc_rate_map_2040s.reshape(155,191) # 2079~2098年における収量増加率を計算 y_pred_2090s = Tmean_year_df.loc[(Tmean_year_df["year"] >= 2079) & (Tmean_year_df["year"] <= 2098),["gid","y_pred"]].groupby("gid")["y_pred"].mean() inc_rate_2090s = y_pred_2090s/y_pred_1990s inc_rate_map_2090s = np.empty(191*155) inc_rate_map_2090s[:] = np.nan inc_rate_map_2090s[inc_rate_2090s.index.astype(int).values] = inc_rate_2090s.values inc_rate_map_2090s = inc_rate_map_2090s.reshape(155,191) # geotif形式で保存 inc_rate_map = np.stack([inc_rate_map_2040s,inc_rate_map_2090s]) inc_rate_ds = xr.Dataset( { "increase_rate":(["era","y","x"],inc_rate_map) }, coords = { "y": sl_gtif.coords["y"], "x": sl_gtif.coords["x"], "era":("era",["2040s","2090s"]) }, ) inc_rate_ds.increase_rate.rio.to_raster("inc_rate_map.tif")
QGISに読み込んでみる
2030~2049年における収量増加率

2079~2098年における収量増加率

ヒストグラム化
import plotly.graph_objects as go fig = go.Figure() fig.add_trace(go.Histogram(x=inc_rate_2040s,name="2040s")) fig.add_trace(go.Histogram(x=inc_rate_2090s,name="2090s")) fig.update_layout(barmode='overlay',xaxis_title_text="増加率") fig.update_traces(opacity=0.75) fig.show()

1980〜1999年に比べ、2030〜2049年は約7%〜18%、2079〜2098年は約18~70%、10a当たり収量(生産性)が向上し、特に北日本で顕著であると予測されました。
公開されているデータを用いて「かんしょ」の10a当たり収量予測モデルを作成し、気候予測モデルのデータを当てはめて将来予測するまでを紹介しました。
ここでは説明変数が1つの最もシンプルなモデルを用いています。これをベースモデルとし、より複雑なモデルの検討や性能向上、他の作物への展開も試して行きたいですね。
※本記事では文部科学省「統合的気候モデル高度化研究プログラム」において、地球シミュレータを用いて作成されたデータを使用しました。
気候変動が進んだ将来、「かんしょ」の生産はどのように変化するか? ―その1 10a当たり収量予測モデルの作成―
はじめに
私事ですが、先月無事に某育成講座を終了し、晴れて「気象データアナリスト」を名乗ることができるようになりました。
講座の終了要件として、"気象データに関連する業務課題を⾃分で設定し、分析提案書および分析報告書を作成せよ"という課題があり、「温暖化に伴うかんしょの生産性変化予測」と題して、かんしょの生産性と気候条件の分析、モデルの構築、温暖化した将来の変化予測を行いましたので、その内容を紹介します。
背景
温暖化により様々な作物で栽培に有利な温度帯が北上してきています。北海道では最近、これまで気候が冷涼なため栽培に不適とされていた「かんしょ」の生産が増えてきています。
これまで「かんしょ」を作ってこなかった地域で新たに産地を形成をするには、ただ植える作物を変えれば良いというわけではなく、苗を確保し、土地にあった品種を選び、流通体制を整えるなど、生産体制を構築する必要があります。しかし、温暖化が進んだ将来、その地域の気象が本当に「かんしょ」を作れるのか?どれくらい増産できるか?の情報がなければ体制構築への投資を判断することが困難です。
そこでかんしょの生産と気象の関係を分析し、温暖化に伴いその生産性がどの程度変化するかを予測することを試みました。
使用データ
気象データ
気象データはアメダスデータを使用しています。今回は以下のデータを使用させていただきました。
この中から、農耕地の実態を反映する地点として"耕地モニタリング地点データベース"に採用されているアメダス地点のデータを各都道府県別に集計し、都道府県別の気象データとしました。
かんしょの生産量データ
e-statで公開されている農林水産省の作物統計調査のうち、収穫量累年統計(かんしょ)の都道府県別集計表のデータを使用しました。
かんしょの生産量データの特徴解析(予測モデルの設計)
かんしょの生産量データについて統計的特徴を把握し、どのような予測モデルを構築するかを検討します。
県別集計
生産量データに収録されている収穫量、作付け面積、10aあたり収量について都道府県別に集計してグラフ化してみます。
データの処理とグラフ化
%cd /mnt/c/Users/hoge/kansyo/ import numpy as np import pandas as pd import plotly.express as px # データの読み込みとグラフ用の変数作成 prefec_kansyo_df = pd.read_pickle("prefec_kansyo_pkl") prefec_id_columns = ["01","02","03","04","05","06","07", "15","16","17","18", "08","09","10","11","12","13","14","19","20", "21","22","23","24", "25","26","27","28","29","30", "31","32","33","34","35", "36","37","38","39", "40","41","42","43","44","45","46","47"] prefec_names = prefec_kansyo_df[["prefec_id","prefec_name"]].drop_duplicates() x_alias = { x[1]:x[2] for x in prefec_names.itertuples()} # 収穫量データの切り出し amount_df = prefec_kansyo_df.set_index(["prefec_id","year"])["収穫量"] amount_df.loc[~amount_df.str.isnumeric()] = np.nan amount_df = amount_df.astype(float) amount_df = amount_df.unstack(level=0) amount_df = amount_df[prefec_id_columns] # 作付け面積データの切り出し area_df = prefec_kansyo_df.set_index(["prefec_id","year"])["作付面積"] area_df.loc[~area_df.str.isnumeric()] = np.nan area_df = area_df.astype(float) area_df = area_df.unstack(level=0) area_df = area_df[prefec_id_columns] yield_df = prefec_kansyo_df.set_index(["prefec_id","year"])["10a当たり収量"] yield_df.loc[~yield_df.str.isnumeric()] = np.nan yield_df = yield_df.astype(float) yield_df = yield_df.unstack(level=0) yield_df = yield_df[prefec_id_columns] # 収穫量のグラフ作成 fig = px.box(amount_df,width=700, height=400) fig.update_layout(title="収穫量の都道府県別集計",yaxis_title=u"収穫量(t)") fig.update_xaxes(title_text="都道府県",labelalias=x_alias) for id in [6.5,10.5,19.5,24.5,29.5,34.5,38.5]: fig.add_vline(x=id,line_color="white") fig.add_annotation(x=11, y=200000, text="茨城県", showarrow=True, arrowhead=2) fig.add_annotation(x=14, y=30000, text="埼玉県", ay=-20, showarrow=True, arrowhead=2) fig.add_annotation(x=15, y=170000, text="千葉県", showarrow=True, arrowhead=2) fig.add_annotation(x=21, y=50000, text="静岡県", showarrow=True, arrowhead=2) fig.add_annotation(x=22, y=30000, text="愛知県", ax=20, ay=-20, showarrow=True, arrowhead=2) fig.add_annotation(x=35, y=40000, text="徳島県", showarrow=True, arrowhead=2) fig.add_annotation(x=38, y=30000, text="高知県", ay=-15,ax=-5, showarrow=True, arrowhead=2) fig.add_annotation(x=41, y=60000, text="長崎県", showarrow=True, arrowhead=2) fig.add_annotation(x=44, y=130000, text="宮崎県", showarrow=True, arrowhead=2) fig.add_annotation(x=45, y=600000, text="鹿児島県", showarrow=True, arrowhead=2) fig.add_annotation(yref="paper", x=3, y=1.07, xanchor="center", showarrow=False, text="北海道 東北") fig.add_annotation(yref="paper", x=8.5, y=1.07, showarrow=False, text="北陸") fig.add_annotation(yref="paper", x=15, y=1.07, showarrow=False, text="関東 東山") fig.add_annotation(yref="paper", x=22, y=1.07, showarrow=False, text="東海") fig.add_annotation(yref="paper", x=27, y=1.07, showarrow=False, text="近畿") fig.add_annotation(yref="paper", x=32, y=1.07, showarrow=False, text="中国") fig.add_annotation(yref="paper", x=36.5, y=1.07, showarrow=False, text="四国") fig.add_annotation(yref="paper", x=42, y=1.07, showarrow=False, text="九州 沖縄") fig.write_image("images/prefec_amount.jpeg") # 作付け面積の都道府県別集計 fig = px.box(area_df) fig.update_layout(title="作付け面積の都道府県別集計",yaxis_title=u"作付け面積") fig.update_xaxes(title_text="都道府県",labelalias=x_alias) for id in [6.5,10.5,19.5,24.5,29.5,34.5,38.5]: fig.add_vline(x=id,line_color="white") fig.add_annotation(x=11, y=9000, text="茨城県", showarrow=True, arrowhead=2) fig.add_annotation(x=14, y=1800, text="埼玉県", ay=-20, showarrow=True, arrowhead=2) fig.add_annotation(x=15, y=7500, text="千葉県", showarrow=True, arrowhead=2) fig.add_annotation(x=21, y=2000, text="静岡県", showarrow=True, arrowhead=2) fig.add_annotation(x=22, y=1800, text="愛知県", ax=20, ay=-20, showarrow=True, arrowhead=2) fig.add_annotation(x=35, y=1500, text="徳島県", showarrow=True, arrowhead=2) fig.add_annotation(x=38, y=1500, text="高知県", ay=-15,ax=-5, showarrow=True, arrowhead=2) fig.add_annotation(x=41, y=2500, text="長崎県", showarrow=True, arrowhead=2) fig.add_annotation(x=44, y=4500, text="宮崎県", showarrow=True, arrowhead=2) fig.add_annotation(x=45, y=20500, text="鹿児島県", showarrow=True, arrowhead=2) fig.add_annotation(xref="paper",yref="paper", x=-0.01, y=1.07, showarrow=False, text="北海道 東北") fig.add_annotation(xref="paper",yref="paper", x=0.16, y=1.07, showarrow=False, text="北陸") fig.add_annotation(xref="paper",yref="paper", x=0.27, y=1.07, showarrow=False, text="関東 東山") fig.add_annotation(xref="paper",yref="paper", x=0.47, y=1.07, showarrow=False, text="東海") fig.add_annotation(xref="paper",yref="paper", x=0.58, y=1.07, showarrow=False, text="近畿") fig.add_annotation(xref="paper",yref="paper", x=0.72, y=1.07, showarrow=False, text="中国") fig.add_annotation(xref="paper",yref="paper", x=0.81, y=1.07, showarrow=False, text="四国") fig.add_annotation(xref="paper",yref="paper", x=0.97, y=1.07, showarrow=False, text="九州 沖縄") fig.write_image("images/prefec_area.jpeg") # 10aあたり収量の都道府県別集計 fig = px.box(yield_df,width=700, height=400) fig.update_layout(title="10a当たり収量の都道府県別集計",yaxis_title=u"10a当たり収量(t)") fig.update_xaxes(title_text="都道府県",labelalias=x_alias) for id in [6.5,10.5,19.5,24.5,29.5,34.5,38.5]: fig.add_vline(x=id,line_color="white") fig.add_annotation(x=0, y=2300, text="北海道", showarrow=True, ax=10, arrowhead=2) fig.add_annotation(x=11, y=2600, text="茨城県", showarrow=True, arrowhead=2) fig.add_annotation(x=15, y=2500, text="千葉県", showarrow=True, arrowhead=2) fig.add_annotation(x=20, y=2530, text="岐阜県", showarrow=True, arrowhead=2) fig.add_annotation(x=35, y=2400, text="徳島県", ax=-20, showarrow=True, arrowhead=2) fig.add_annotation(x=42, y=2400, text="大分県", ax=-30,ay=-10, showarrow=True, arrowhead=2) fig.add_annotation(x=44, y=2600, text="宮崎県", ax=-30,ay=-10, showarrow=True, arrowhead=2) fig.add_annotation(x=45, y=2900, text="鹿児島県", ax=-30,ay=-20, showarrow=True, arrowhead=2) fig.add_annotation(x=46, y=1905, text="沖縄県", ax=-10,ay=0, showarrow=True, arrowhead=2) fig.add_annotation(yref="paper", x=3, y=1.07, xanchor="center", showarrow=False, text="北海道 東北") fig.add_annotation(yref="paper", x=8.5, y=1.07, showarrow=False, text="北陸") fig.add_annotation(yref="paper", x=15, y=1.07, showarrow=False, text="関東 東山") fig.add_annotation(yref="paper", x=22, y=1.07, showarrow=False, text="東海") fig.add_annotation(yref="paper", x=27, y=1.07, showarrow=False, text="近畿") fig.add_annotation(yref="paper", x=32, y=1.07, showarrow=False, text="中国") fig.add_annotation(yref="paper", x=36.5, y=1.07, showarrow=False, text="四国") fig.add_annotation(yref="paper", x=42, y=1.07, showarrow=False, text="九州 沖縄") fig.write_image("images/prefec_yield.jpeg")
結果



生産量は、主産地の鹿児島、宮崎、茨城、千葉で多いことがわかりますが、低緯度の都道府県で多く、高緯度の都道府県で少ないという傾向ははっきりとしていません。
作付け面積は生産量と全く同じ傾向があり、かんしょの生産量は作付面積の大きさに依存していることがわかります。
また、首都圏、中京圏、関西圏に近い県で作付面積が大きいことから、生産量の大きさは大消費地からの近さやブランドの有無など、気候以外の要因が影響していると考えられます。
10aあたり収量は、主産地で高く、その他にも高い県が存在していました。また、高緯度の東北4県では比較的低く、北海道を除けばうっすらと南高北低の傾向があるように見えますが、作付け面積と同様に気候以外の要因が大きく影響していると考えられます。
収穫量と作付面積の時系列変化
次に収穫量と作付け面積の時系列を積み重ね線グラフにしてみます。
# 欠測値をリニア補間する inertpolate_amount_df = amount_df.interpolate(method="linear") inertpolate_area_df = area_df.interpolate(method="linear") # 生産量の時系列グラフの作成 fig = px.area(inertpolate_amount_df[amount_df.loc[2017].sort_values().index.values].rename(columns=x_alias)) fig.update_layout(title="生産量の時系列",legend_traceorder="reversed",yaxis_title="収穫量(t)",legend_title="都道府県",font=dict(family="Noto Sans CJK JP")) fig.write_image("images/trend_amount.jpeg") # 作付面積の時系列グラフの作成 fig = px.area(inertpolate_area_df[area_df.loc[2017].sort_values().index.values].rename(columns=x_alias)) fig.update_layout(title="作付け面積の時系列",legend_traceorder="reversed",yaxis_title="作付面積(ha)",legend_title="都道府県",font=dict(family="Noto Sans CJK JP")) fig.write_image("images/trend_area.jpeg")


総収穫量と作付面積は共に減少傾向にあり、変化傾向もほぼ同じであることから、作付面積が減ってきていることが原因で総収穫量も減ってきていると考えて良さそうです。
10a当たり収量の時系列変化
10aあたり収量については標準化してからグラフ化することで、都道府県間の収量変動の地域差や共通する傾向を把握します。
# 標準化ツールの読み込み from sklearn.preprocessing import StandardScaler std_scaler = StandardScaler() std_scaler.fit(yield_df) # 標準化 yield_std = pd.DataFrame(std_scaler.transform(yield_df), columns=yield_df.columns,index=yield_df.index) # 10a当たり収量の時系列変化 fig = px.line(yield_std[amount_df.loc[2017].sort_values().index.values].rename(columns=x_alias)) fig.update_layout(title="10a当たり収量の時系列",yaxis_title=u"10a当たり収量",legend_traceorder="reversed",font=dict(family="Noto Sans CJK JP")) fig.write_image("images/trend_yield.jpeg")

増加・減少傾向は見られませんでしたが、特に1995年より前において、豊作、不作の波が一致しているように見え、これは全国的な気象条件の変動を反映していると考えられます。
以上の解析から、構築する予測モデルは
- 10a当たりの収量を目的変数とする
- 気候以外の要因についてモデル化する
こととしました。
予測モデルの作成
気候以外の要因をモデル化するため、気候要因を固定効果、気候以外の要因はまとめてランダム効果として推定する線形混合モデルを構築します。
ここではモデルを単純化するため、生育期間(4〜10月)の平均気温のみを説明変数としたベイズモデルを作成し、pymcを用いてパラメータ推定を行いました。
import numpy as np import pandas as pd import pymc import plotly.express as px import arviz as az import pickle # データの読み込み prefec_month_df = pd.read_pickle("prefec_month_mean.pkl") prefec_kansyo_df = pd.read_pickle("prefec_kansyo_pkl") # 10a当たり収量データの整形 yield_df = prefec_kansyo_df.set_index(["prefec_id","year"])["10a当たり収量"] yield_df.loc[~yield_df.str.isnumeric()] = np.nan yield_df = yield_df.astype(float) # 4〜10月の平均気温を計算 Tmean = prefec_month_df.loc[prefec_month_df["month_MM"].isin([4,5,6,7,8,9,10])].groupby(["prefecture_id","year_YY"])['T_mean'].apply(lambda x: x.mean(skipna=False)) Tmean.name = "T_mean" Tmean.index.names = yield_df.index.names data_df = pd.concat([yield_df.to_frame(),Tmean.to_frame()],axis=1) data_df = data_df.dropna().reset_index() # 都道府県のワンホットベクトルを作成 prefec_df = pd.get_dummies(data_df["prefec_id"]) with pymc.Model() as model: # 次元を定義 model.add_coord("data",data_df.index,mutable=True) model.add_coord("n_prefec",prefec_df.columns,mutable=True) model.add_coord("n_feature",[1],mutable=True) # データ読み込み X = pymc.Data("X",data_df[["T_mean"]],dims=("data","n_feature"),mutable=True) y = pymc.Data("y",data_df["10a当たり収量"],dims=("data",),mutable=True) prefec_arr = pymc.Data("prefec_arr",prefec_df,dims=("data","n_prefec"),mutable=True) # 事前分布 r_sigma = pymc.HalfCauchy("r_sigma", beta=10) sigma = pymc.HalfCauchy("sigma", beta=10) intercept = pymc.Normal("Intercept", 0, sigma=20) slope = pymc.Normal("slope", 0, sigma=20,dims=("n_feature",)) r_intercept = pymc.Normal("r_intercept", 0, sigma=r_sigma ,dims=("n_prefec",)) random_effect = pymc.Deterministic("random_effect",pymc.math.dot(prefec_arr, r_intercept),dims=("data",)) # 尤度関数の設定 mu = pymc.Deterministic("mu",random_effect + intercept + pymc.math.dot(slope,X.T),dims=("data",)) likelihood = pymc.Normal("lklh", mu=mu, sigma=sigma, observed=y) # サンプリング idata = pymc.sample(3000,idata_kwargs={'log_likelihood':True}) # 結果の保存 with open("model_result.pkl","wb") as f: pickle.dump(idata,f)
模式図を表示
pymc.model_to_graphviz(model)

サンプリング結果をプロット
az.plot_trace(idata)
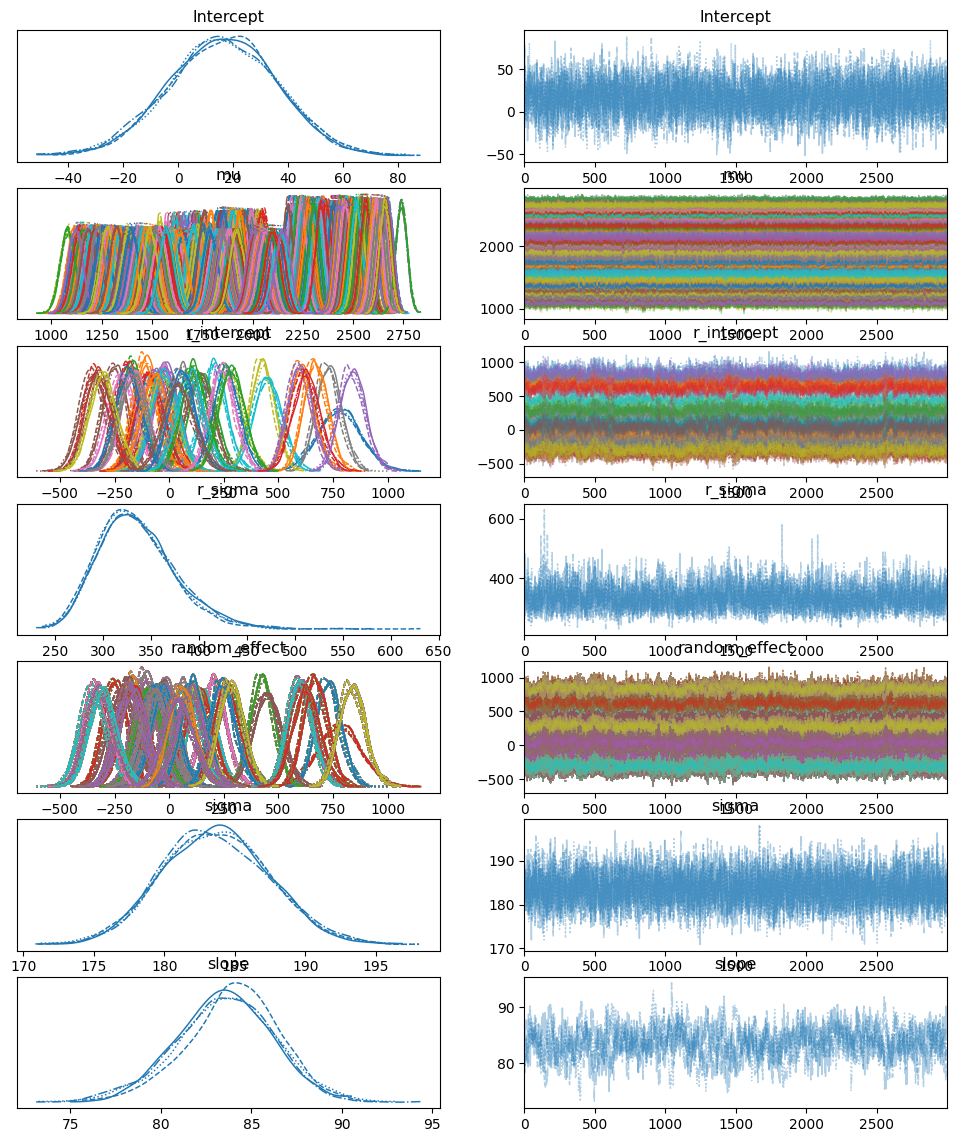
まく混交&収束していそうです。
モデルの評価
Observed-Predicted Plot (yyplot)を作成してみます。
# ランダムエフェクトを覗いた潜在的10a当たり収量を計算 slope = np.atleast_1d(idata.posterior["slope"].mean().data)[0] intercept = np.atleast_1d(idata.posterior["Intercept"].mean().data)[0] data_df["random_effect"] = idata.posterior["random_effect"].mean(dim=["chain","draw"]).data data_df["潜在的収量の予測"] = data_df["T_mean"]*slope+intercept data_df["潜在的収量"] = data_df["10a当たり収量"] - data_df["random_effect"] # Observed-Predicted Plot (yyplot) fig = px.scatter(data_df,x="潜在的収量の予測",y="潜在的収量",opacity=0.5) fig.add_scatter(x=[800,2500],y=[800,2500]) fig.update_layout(width=430,height=400,margin=dict(l=20, r=20, t=20, b=20),showlegend=False) fig.update_xaxes(range=[800, 2500]) fig.update_yaxes(range=[800, 2500],tick0=1000,dtick=500) fig.show()

説明変数が1つの非常に単純なモデルですので、潜在的収量が大きいところで実測よりも予測が小さく、残念ながら平均気温の上昇に対する収量増加をうまく再現できていません。
実際には、説明変数を増やし説明力の高いモデルを作成する必要がありますが、そこはとりあえず目を瞑って、このモデルを使って将来予測を行いたいと思います。
→その2につづく
これまでの気候の変化(観測結果)を解析する
はじめに
先日、9th GEWEX-OSC 市民講座 「みんなで考えるこれからの気候変動」にオンライン参加しました。
札幌管区気象台からの話題提供で、北海道全体での気温の上昇傾向について紹介されていたのですが、その中で(恣意的に分割した場合という前提で)温暖化のスピードが1990年代に加速しているようにみえるのでは?とのこと。
ここにデータが公開されているので入手してグラフ化してみると、
%cd cd /mnt/c/Users/hoge/AMeDAS/SapporoKanku/import numpy as np import pandas as pd import plotly.express as px from sklearn import linear_model
hokkaido_tmean_df = pd.read_csv("hokkaido_tmean_ann_obs.csv") hokkaido_tmean_df.columns = ["year","tmean"]
fig = px.scatter(hokkaido_tmean_df,x="year",y="tmean",width=800,height=500,trendline='ols',trendline_color_override='orange',) fig.update_traces(selector=0,marker_size=8,mode="lines+markers") fig.update_traces(selector=1,line_width=6) fig.update_layout(margin=dict(l=60, r=20, t=20, b=20)) fig.update_xaxes(title="年") fig.update_yaxes(title="1991-2020年平均からの差(℃)")

たしかに1990年代以前と以降で別々の線を書きたくなります。
本当に1990年代にトレンドが変化したのか?長期的なトレンド+年々変動のばらつきの範囲内なのか?変化点解析を行ってみました。
データの入手と整形
札幌管区気象台のホームページで公開されている「北海道地方のこれまでの気候の変化(観測結果)」から、長期間観測を継続している6地点(旭川、網走、札幌、帯広、根室、函館)の年平均気温データを入手しました。
%cd cd /mnt/c/Users/hoge/AMeDAS/SapporoKanku/import numpy as np import pandas as pd import plotly.express as px
data_df = pd.DataFrame(index=[])
for h_name in ["abashiri","asahikawa","hakodate","nemuro","obihiro","sapporo" ]: tdf = pd.read_csv(f"{h_name}_tmean_ann_obs.csv") tdf.columns = ["year","tmean"] tdf["sta_name"] = h_name data_df = pd.concat([data_df,tdf])
data_df = data_df.set_index(["sta_name","year"]).unstack(level=0) data_df = data_df.dropna() data_df.columns = data_df.columns.get_level_values(1)
fig = px.line(data_df,width=800,height=500) fig.update_xaxes(title="年") fig.update_yaxes(title="年平均気温(℃)")
1991-2020年平均からの差を計算する data_std_df = data_df - data_df.loc[1991:2020].mean()
fig = px.line(data_std_df,width=800,height=500) fig.update_xaxes(title="年") fig.update_yaxes(title="1991-2020年平均からの差(℃)")

モデル構築
前提として、次の条件を設定しました。
- 変曲点は1つ
- 変曲点の前後は直線のトレンド
- すべての地点でトレンドの変化は同時に起こっている
- 年々変動のばらつきはすべての地点で同じ
変化点の前と後でトレンドが変化するモデルを以下の式で定義しました
ここで、はトレンドが変化する年、
は年々変動のばらつきで、
年に傾きが
から
に変化するようにしています。
pymcでモデルを組み立て、サンプリングします。
import pymc importwith pymc.Model() as model: #次元・インデックスを定義 model.add_coord("year",data_std_df.index,mutable=True) model.add_coord("sta",data_std_df.columns,mutable=True) model.add_coord("period",[0,1],mutable=True) n_year = data_std_df.shape[0] n_sta = data_std_df.shape[1] #データ読み込み X=pymc.Data("X",np.arange(n_year),dims=("year",),mutable=True) y=pymc.Data("y",data_std_df,dims=("year","sta"),mutable=True) #事前分布 sigma = pymc.HalfCauchy("sigma", beta=10) intercept = pymc.Normal("intercept", 0, sigma=20,dims=("sta",)) slope = pymc.Normal("slope", 0, sigma=20,dims=("sta","period")) cp = pymc.DiscreteUniform('cp', lower=0, upper=n_year-2) #muの計算 X_bcast = pymc.math.broadcast_to(X,[n_sta,n_year]) mu1 = pymc.Deterministic("mu1",intercept[:]+ slope[:,0]X_bcast.T,dims=("year","sta",)) mu2 = pymc.Deterministic("mu2",(intercept[:]+(slope[:,0] - slope[:,1])cp) + slope[:,1]*X_bcast.T,dims=("year","sta",)) #変化点での切り替え idx = pymc.math.broadcast_to(np.arange(n_year),[n_sta,n_year]).T mu = pymc.math.switch(idx <= cp, mu1, mu2) #尤度 likelihood = pymc.Normal("lklh", mu=mu, sigma=sigma, observed=y) #サンプリング idata = pymc.sample(3000,idata_kwargs={'log_likelihood':True})
模式図を表示
pymc.model_to_graphviz(model)

サンプリング結果をプロット
az.plot_trace(idata)

うまく混交&収束していそうです。
結果1 トレンドが変化した年
cpのサンプリング結果から、いつトレンドが変化していそうか?を見ることができます。
import plotly.express as px fig = px.histogram(x=data_std_df.index[idata.posterior["cp"].data.flatten()],width=500,height=400) fig.update_xaxes(title="年") fig.update_layout(margin=dict(l=40, r=20, t=20, b=20))

1975~1991年まで分布しており、グラフの見た目と一致しています。そのうち1985年が最も多く、この年にトレンドが変化していると考えて良さそうです。
結果2 傾きの変化
slopeのサンプリング結果から、それぞれの地点で傾きがどの程度変化しているかを見ることができます
from plotly.subplots import make_subplots import plotly.graph_objects as go fig = make_subplots(rows=6, cols=1,subplot_titles=("旭川", "札幌", "網走","根室","帯広","函館"),shared_xaxes=True,vertical_spacing=0.02,x_title="傾き")fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="asahikawa",period=0).data.flatten(),name="変曲前",marker=go.histogram.Marker(color="lightblue"),legendgroup = '1'),row=1, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="asahikawa",period=1).data.flatten(),name="変曲後",marker=go.histogram.Marker(color="lightsalmon"),legendgroup = '1'),row=1, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="sapporo",period=0).data.flatten(),name="変曲前",marker=go.histogram.Marker(color="lightblue"),showlegend=False),row=2, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="sapporo",period=1).data.flatten(),name="変曲後",marker=go.histogram.Marker(color="lightsalmon"),showlegend=False),row=2, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="abashiri",period=0).data.flatten(),name="変曲前",marker=go.histogram.Marker(color="lightblue"),showlegend=False),row=3, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="abashiri",period=1).data.flatten(),name="変曲後",marker=go.histogram.Marker(color="lightsalmon"),showlegend=False),row=3, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="nemuro",period=0).data.flatten(),name="変曲前",marker=go.histogram.Marker(color="lightblue"),showlegend=False),row=4, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="nemuro",period=1).data.flatten(),name="変曲後",marker=go.histogram.Marker(color="lightsalmon"),showlegend=False),row=4, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="obihiro",period=0).data.flatten(),name="変曲前",marker=go.histogram.Marker(color="lightblue"),showlegend=False),row=5, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="obihiro",period=1).data.flatten(),name="変曲後",marker=go.histogram.Marker(color="lightsalmon"),showlegend=False),row=5, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="hakodate",period=0).data.flatten(),name="変曲前",marker=go.histogram.Marker(color="lightblue"),showlegend=False),row=6, col=1) fig.add_trace(go.Histogram(x=idata.posterior["slope"].sel(sta="hakodate",period=1).data.flatten(),name="変曲後",marker=go.histogram.Marker(color="lightsalmon"),showlegend=False),row=6, col=1)
for anot in fig.layout.annotations[:-1]: anot.update(x=0.06,yshift=-25) fig.update_layout(barmode='overlay',height=800,width=500,legend_x=0.8,legend_y=0.99,margin=dict(l=30, r=10, t=20, b=50))

旭川や札幌で変化量が小さく、道東、道南では大きく変化しているようです。
結果3 :北海道地方の平均気温トレンドの解析
先程の地点毎の解析で得られた年々変動の分散と変化点を使って、北海道地方の年平均気温のトレンドを解析してみます。
with pymc.Model() as model: # coords model.add_coord("year",hokkaido_df["year"],mutable=True) model.add_coord("period",[0,1],mutable=True) n_year = hokkaido_df.shape[0] # data X=pymc.Data("X",np.arange(n_year),dims=("year",),mutable=True) y=pymc.Data("y",hokkaido_df["tmean"],dims=("year",),mutable=True) # Set parameter sigma = 0.529 cp = np.argwhere(hokkaido_df["year"] == data_std_df.index[92])[0][0] # Define priors intercept = pymc.Normal("intercept", 0, sigma=20) slope = pymc.Normal("slope", 0, sigma=20,dims=("period")) # mu1,mu2 →mu mu1 = pymc.Deterministic("mu1",intercept+ slope[0]X,dims=("year",)) mu2 = pymc.Deterministic("mu2",(intercept+(slope[0] - slope[1])cp) + slope[1]*X,dims=("year",)) idx = np.arange(n_year) mu = pymc.math.switch(idx <= cp, mu1, mu2) # likelihood likelihood = pymc.Normal("lklh", mu=mu, sigma=sigma, observed=y) # sampling idata = pymc.sample(3000,idata_kwargs={'log_likelihood':True})

トレンドのグラフを作成
summary_df = az.summary(idata)cp_x = data_std_df.index[92] cp_y = summary_df.loc["slope[0]","mean"]92+summary_df.loc["intercept","mean"] x_0 = hokkaido_df["year"].min() y_0 = summary_df.loc["intercept","mean"] x_1 = hokkaido_df["year"].max() y_1 = summary_df.loc["slope[1]","mean"](x_1 - cp_x) + cp_y
fig = px.scatter(hokkaido_df,x="year",y="tmean",width=800,height=500) fig.update_traces(selector=0,marker_size=8,mode="lines+markers") fig.update_layout(margin=dict(l=60, r=20, t=20, b=20)) fig.update_xaxes(title="年") fig.update_yaxes(title="1991-2020年平均からの差(℃)") fig.add_shape(type="line",x0=x_0, y0=y_0, x1=cp_x, y1=cp_y,line=dict(width=6,color='orange')) fig.add_shape(type="line",x0=cp_x, y0=cp_y, x1=x_1, y1=y_1,line=dict(width=6,color='orange'))

1984年にトレンドが変化するグラフになりました。
終わりに
観測データのトレンドが1984年に変化しているからといって、その年になにかイベントがあったということではありません。(相関と因果を混同してはいけない)
ただ近年、温暖化が加速していることについてはいろいろ議論されているようです。
一昔前の「ハイエイタス」の議論の逆パターンで、今回解析した短期の傾向がそのまま「人為的地球温暖化」が加速している証拠にはならないことに注意が必要です。
ただ、地球沸騰化の実感とは一致しているかも。
気候予測データの解析環境を構築する 番外編― ”wxbcgribx.py”を動かす
はじめに
「気象ビジネス推進コンソーシアム(略称:WXBC)」により、 気象庁のGPVデータを処理し活用する方法を学ぶため、気象庁GPVデータ分析チャレンジ!入門(2023年10月26日)が開催されています。(現在受講中)
事前準備として、” WXBCオリジナルPythonライブラリwxbcgribX”の実行環境を作っておく必要があるとのこと。
試行錯誤してWSL2-Docker下で動くようにしましたので、紹介します。
wgrib2のコマンドパスの設定
wxbcgribx.pyの36行目に次のパスを設定します
wgrib2 = "docker exec -w /mnt/c/Users/hoge/{作業ディレクトリ} wgrib2_dock wgrib2" #wgrib2 = Path("C:/wgrib2/wgrib2.exe") # wgrib2のインストール場所 Windowsの場合 #wgrib2 = Path("/usr/local/bin/wgrib2.exe") # wgrib2のインストール場所 Linuxの場合 #wgrib2 = Path("~/work/grib2/wgrib2/wgrib2") # wgrib2のインストール場所 Macの場合
一時フォルダの設定
私の環境では、tempfile.TemporaryDirectory()が動かないので、作業ディレクトリに”tmp"フォルダを作成して、そこを使うように設定します。
def from_grb(grbpath,matchopt,verbose): """ gpvデータをGRIB2ファイルから取得する関数 matchopt: データを選別するオプション文字列 """ #指定した気象要素のデータを取り出して一時ファイルに格納 with tempfile.TemporaryDirectory() as td: Path("./tmp").mkdir(exist_ok = True) #作業フォルダの作成 #dumppath = Path(td)/"extracting.nc" #作業ファイルの指定をコメントアウト dumppath = "./tmp/extracting.nc" #作業ファイルの指定を修正 opt = f'{matchopt} -netcdf {dumppath}' rc = wg2(grbpath, opt) if verbose: print(rc.stdout)#.splitlines()) #一時ファイルからデータセットをロード with xr.open_dataset(dumppath) as ds: ds.load() #dumppath.unlink(missing_ok=True) #後片付けをコメントアウト return ds
事前テストのスクリプトが動きました。
これまで構築した、「気候予測データの解析環境」で”wxbcgribx.py”を動かす方法を紹介しました。試してみてくださいね~。
追記:GoogleColabでwgrib2を使うには
講義で出ていたこの質問、
質問です。どうしても、社内では供与PCへのインストールが出来ない環境にあります。GoogleColabでwgrib2を使うにはどうすればよいでしょうか?
調べてみたらこんな記事がありました。
↑この場合、wxbcgribx.pyにおけるwgrib2のコマンドパスは
wgrib2 = "wgrib2"
でOKだと思います。
ご参考に~
追記2: 「気象庁GPVデータ分析チャレンジ!基礎編」の”wxbcgribx.py”を動かす
本日(2023.11.30)開催の「気象庁GPVデータ分析チャレンジ!基礎編」で配布された”wxbcgribx.py”は、バージョンアップされているようでうまく動かず・・・
73行目からの"wg2"で実行されているエラーチェックをコメントアウトすると動きました。
def wg2(src,opt=''): # wgrib2を実行する関数 #if not wgrib2.exists(): # print("wgrib2 をインストールしてください。") # sys.exit() check_path(src) rc = subprocess.run(f'{wgrib2} {opt} {src}', shell=True, text=True, capture_output=True) # print(rc.returncode) # print(rc.stdout) # print(rc.stderr) return rc
気候予測データの解析環境を構築する。その7―MCMCサンプラーの実行環境を構築する。
はじめに
気候予測データは、将来の平均的な「気候」状態を予測するためのもので、ある地域の気温・降水量の平均値や変動の標準偏差などの統計量がどう変化するか?を予測しています。(ココが知りたい地球温暖化より)
気温など、連続した数値でかつ正規分布に従うことがわかっていれば、平均値や分散を求めることは簡単です。しかし、ガンマ分布に従う降水量や離散値である猛暑日日数の変化を単純な算術平均で表すことには問題があります。そのようなデータを扱うには"正規分布以外の確率分布を扱える統計モデル"が有用です。
“階層ベイズモデル”は、様々な確率分布を扱い複雑な統計モデルを構築することができ、マルコフ連鎖モンテカルロ法を用いてサンプリングをすることでパラメータを推計することができます。
Pythonでマルコフ連鎖モンテカルロ法を使うためのライブラリ(MCMCサンプラー)には、PyMC、Pyro, NumPyro, TensorFlowProbability, PyStan, PyJAGSなどがありますが、本研究室では"PyMC"を使っています。
ということで、PyMCの実行環境を構築していきます。
PyMCのインストール
Python標準の"venv"を使って、MCMC用の環境を作成し、PyMCをインストールします。
# 最新の状態に更新 sudo apt update sudo apt upgrade # venvのインストール sudo apt install python3.10-venv # 仮想環境の構築 python3 -m venv v-MCMC # v-MCMCに入る →プロンプトの頭に(v-MCMC)と表示される source v-MCMC/bin/activate # ライブラリの追加 pip3 install scipy pandas pip3 install plotly kaleido matplotlib pip3 install ipykernel pip3 install cloudpickle cachetools arviz pip3 install fastprogress typing-extensions pip3 install pytensor # PyMCのインストール pip3 install pymc pip3 install git+https://github.com/pymc-devs/pymc-experimental.git
VScodeからv-MCMC環境を呼び出す
↓を参考に、VSCodeにvenv環境を認識してもらいます。
GUIでは、右下の「管理」から「設定」を呼び出し、

"venv"で検索して「項目の追加」をクリック

"v-MCMC"と入力してOK

追加される

「表示」→「コマンドパレット」からJupyterインタラクティブシェルを起動



「Python環境」を選択

「v-MCMC」を選択

カーネルが変更される

一般化線形モデルを動かしてみる
PyMCの公式には様々なチュートリアルが公開されています。動作確認に“GLM: Linear regression”を実行してみます。
https://www.pymc.io/projects/docs/en/latest/learn/core_notebooks/GLM_linear.html
まずは環境設定と擬似データを作成
# ライブラリの読み込み import arviz as az import matplotlib.pyplot as plt import numpy as np import pandas as pd import pymc as pm import xarray as xr from pymc import HalfCauchy, Model, Normal, sample # 環境設定 RANDOM_SEED = 8927 rng = np.random.default_rng(RANDOM_SEED) %config InlineBackend.figure_format = 'retina' az.style.use("arviz-darkgrid") # 擬似データ作成 size = 200 true_intercept = 1 true_slope = 2 x = np.linspace(0, 1, size) # y = a + b*x の線形回帰モデル true_regression_line = true_intercept + true_slope * x # データにノイズを加える y = true_regression_line + rng.normal(scale=0.5, size=size) data = pd.DataFrame(dict(x=x, y=y)) # データのグラフを描いてみる fig = plt.figure(figsize=(7, 7)) ax = fig.add_subplot(111, xlabel="x", ylabel="y", title="Generated data and underlying model") ax.plot(x, y, "x", label="sampled data") ax.plot(x, true_regression_line, label="true regression line", lw=2.0) plt.legend(loc=0);

次にモデルを組み立てます。チュートリアルでは一気にサンプリングまでしていますが、ここではまず、モデルを組み立てるところまで。
with Model() as model: # model specifications in PyMC are wrapped in a with-statement # Define priors sigma = HalfCauchy("sigma", beta=10) intercept = Normal("Intercept", 0, sigma=20) slope = Normal("slope", 0, sigma=20) # Define likelihood likelihood = Normal("y", mu=intercept + slope * x, sigma=sigma, observed=y)
チュートリアルにはありませんが、以下のコマンドでモデルの内容を表示できます。
# 定義した各パラメータの情報 display(model.model) # モデル構造 modeldag = pm.model_to_graphviz(model) display(modeldag)

サンプリングを実行
with model: idata = sample(3000)

結果を表示します。 ※チュートリアルでは"bambi"などなるものを使って、Rで使うようなチルダ式を使ってモデルを作成する方法が紹介されていますが、ここでは割愛します。
# サンプリング結果 az.plot_trace(idata, figsize=(10, 7)); # 予測結果を計算 idata.posterior["y_model"] = idata.posterior["Intercept"] + idata.posterior["slope"] * xr.DataArray(x) # 予測結果を描く _, ax = plt.subplots(figsize=(7, 7)) az.plot_lm(idata=idata, y="y", num_samples=100, axes=ax, y_model="y_model") ax.set_title("Posterior predictive regression lines") ax.set_xlabel("x");


動きましたか?
次回はこのPyMCを使って、 「日本域CMIP6データ」を解析したいと思います。
「日本域CMIP6データ」を可視化する その1-データの入手とマップ化
はじめに
「日本域CMIP6データ」は統計的ダウンスケーリング手法を用いて作成された、20世紀初頭から21世紀末までの日単位で全国1kmメッシュの気候予測情報で、5種類の最新の全球気候モデル、3種類の温室効果ガス排出想定に基づいた将来予測データが公開されています。
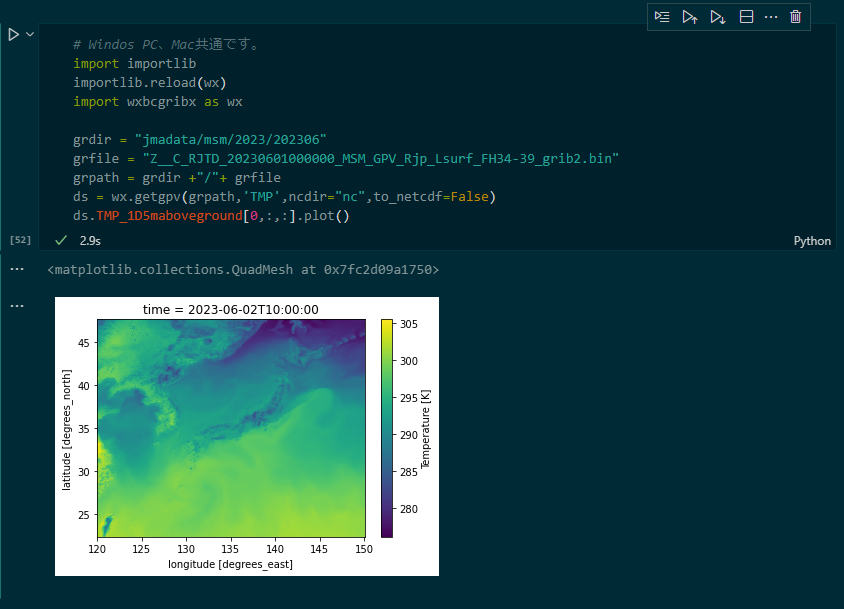
利用可能な 8 変数(日最低・最高・平均気温、降水量、全天日射量、下向き長波放射、風速、相対湿度)のうち日最高気温データについて、まずはマップ化してみましょう。
気候予測データセット(DS2022)のホームページにアクセス
diasjp.netデータセット紹介→日本域CMIP6データに進む

データダウンロードをクリック
"データをダウンロード"をクリック
CMIP6をベースにしたCDFDM手法による日本域バイアス補正気候シナリオデータのダウンロード一覧ページにログイン
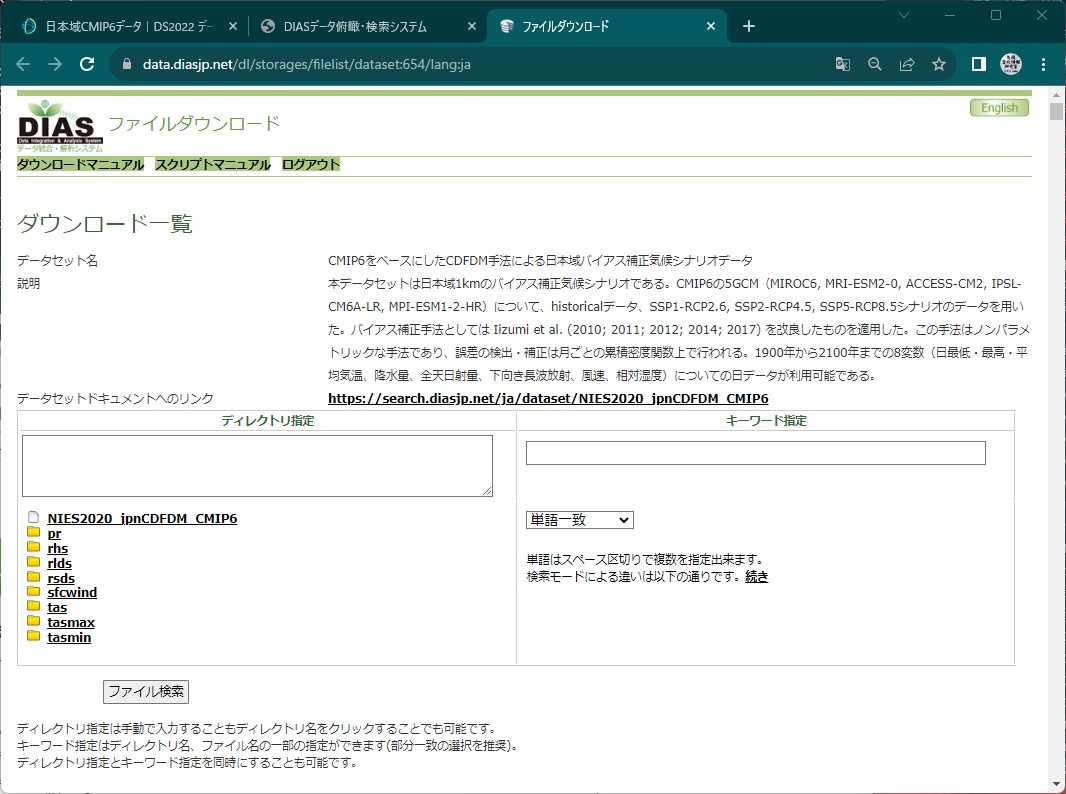
”MRI-ESM2-0”の1950年代の日最高気温データを検索し、全ファイルにチェックを入れる
ディレクトリ指定:/NIES2020_jpnCDFDM_CMIP6/tasmax/day/MRI-ESM2-0/historical キーワード指定:-195(部分一致)

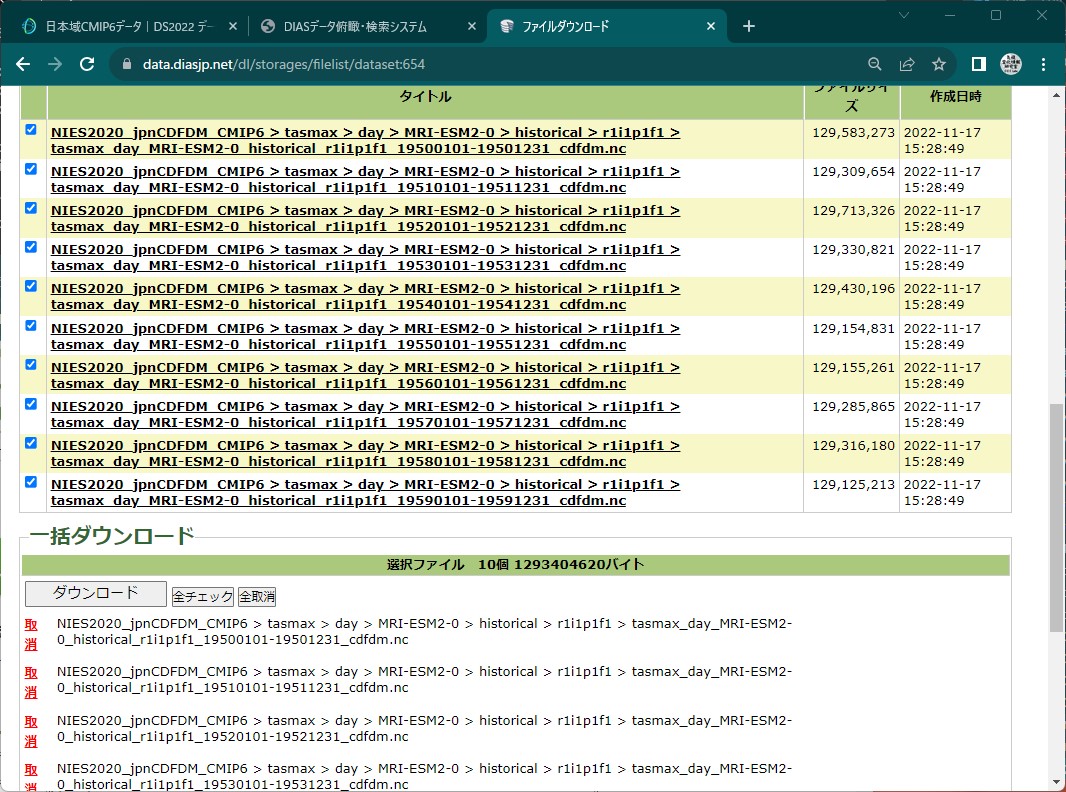
一括ダウンロードする
データを解凍する
# ユーザホームディレクトリにCMIP6フォルダを作成し、 # ダウンロードした”data***.tgz”を移動しておく。 cd /mnt/c/Users/hoge/CMIP6/ find ./ -type f -name "*.tgz" | xargs -n 1 tar zxf
次のディレクトリにデータが解凍されます。
C:\Users\hoge\CMIP6\dias\data\NIES2020_jpnCDFDM_CMIP6\tasmax\day\MRI-ESM2-0
QGISに読み込む
入手したデータはnetcdf形式ですので、そのままQGISに読み込むことができます。
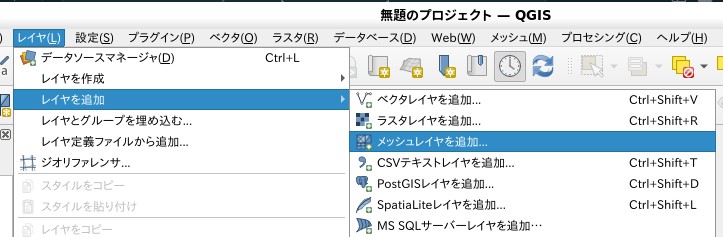
メッシュレイヤとして読み込む
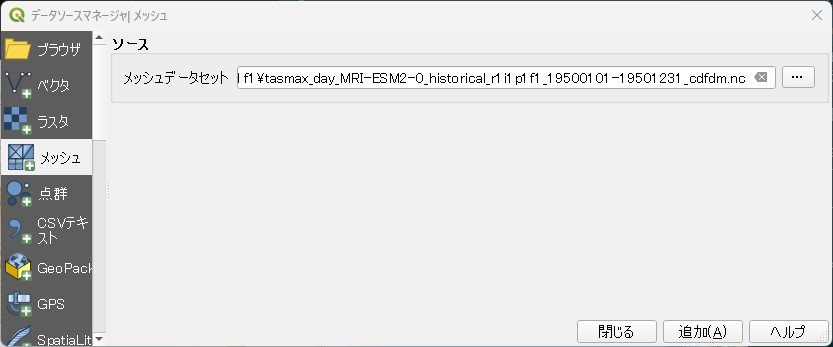
「レイヤ」→「レイヤを追加」→「メッシュレイヤを追加」
ソース:メッシュデータセットに"tasmax_day_MRI-ESM2-0_historical_r1i1p1f1_19500101-19501231_cdfdm.nc"を指定して「追加」
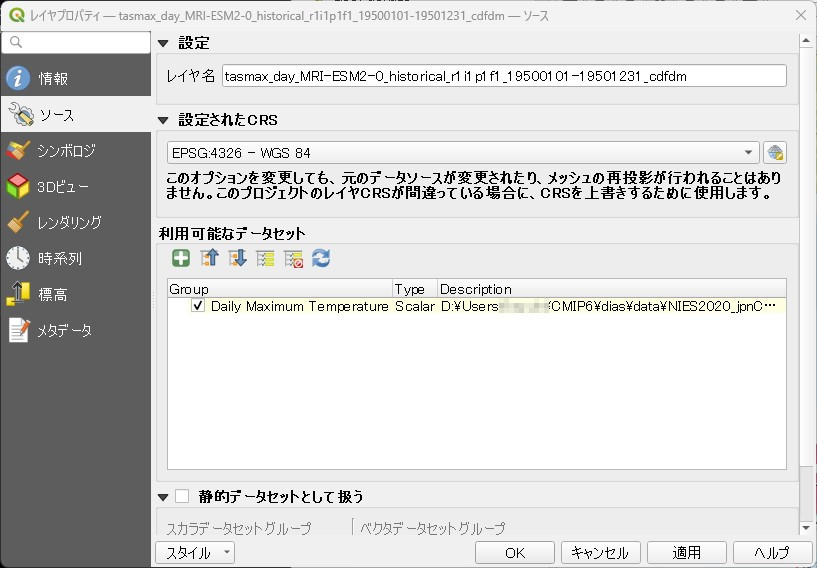
CRSの設定
緯度経度のグリッドですので、EPSG4326をつかいます。
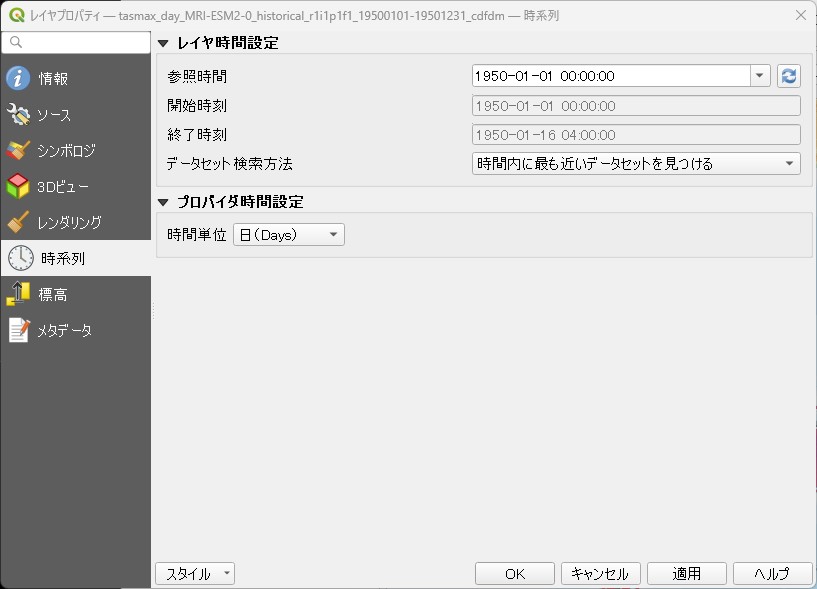
時間設定
レイヤの時間を19500101-19501231になるように設定します。
日最高気温のマップが表示されます 。
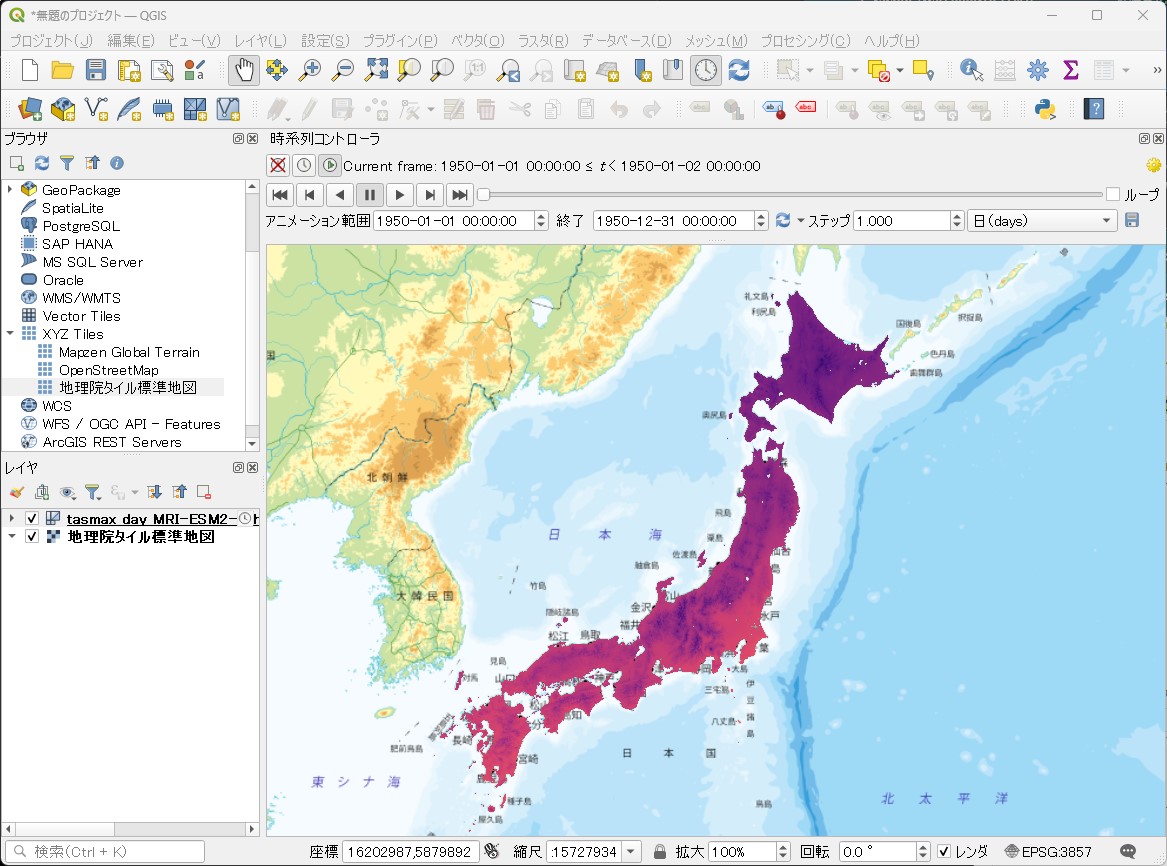
一応アニメーションも動きます。
「日本域CMIP6データ」の日最高気温データを入手し、マップ化するまでを紹介しました。
実は、月平均値なら気候変動適応情報プラットフォームのWebGISで簡単に可視化できます。
adaptation-platform.nies.go.jp
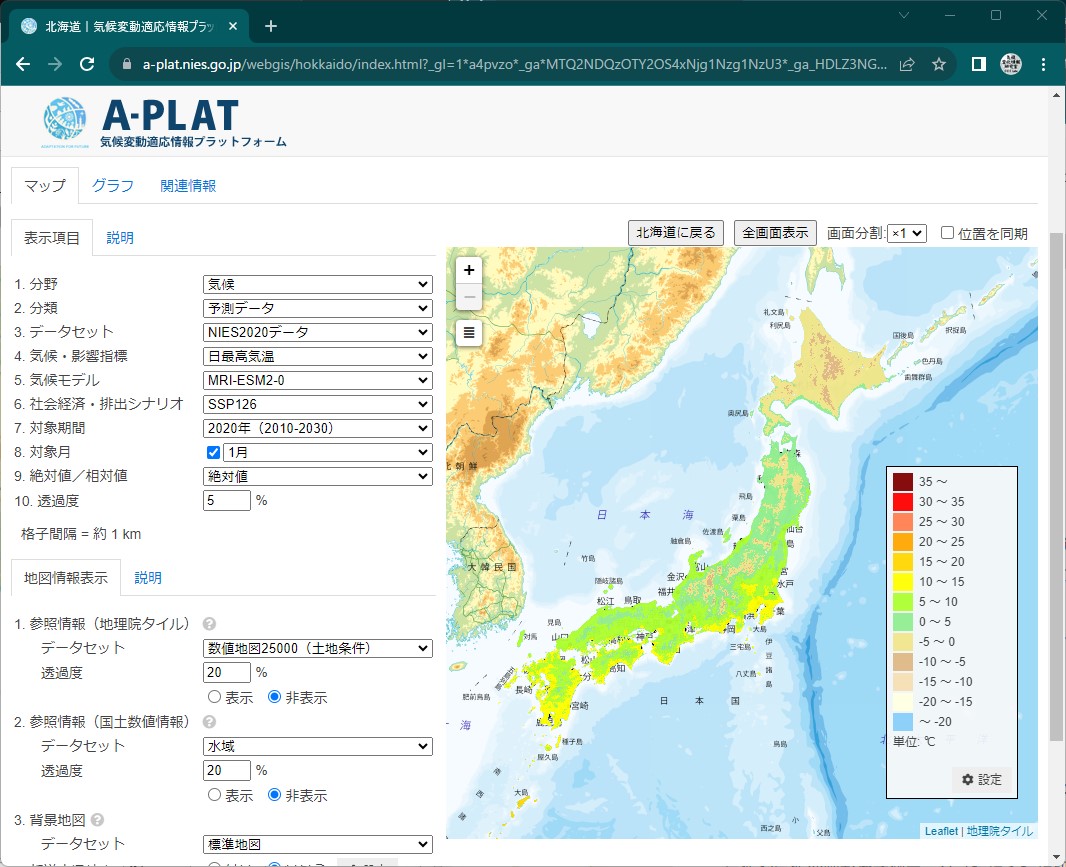
簡単ですので、まずはこちら↑を試してみてください。
次回は、入手したデータからピンポイントの情報を取り出し、集計する方法を紹介したいと思います。
※本記事では以下のデータを利用させていただきました。 石崎 紀子, 2021: CMIP6をベースにしたCDFDM手法による日本域バイアス補正気候シナリオデータ, Ver.1, 国立環境研究所, doi:10.17595/20210501.001. (参照: 2023/09/28~10/01)
「全球及び日本域150年連続実験データ」を可視化する その7-札幌の平均気温のシミュレーション結果をヒートマップで表現する。
はじめに
今年の夏は北海道でもうだるような暑さが続きました。気象庁の”夏の天候のまとめ”によれば、2023年(令和5年)夏(6~8月)の日本の平均気温は1898年以降で夏として最も高くなったとのこと。
別紙(概況、統計値等)によれば、北海道の平均気温は平年より3℃も高かったらしい。
https://www.data.jma.go.jp/obd/stats/data/stat/tenko2023jja_besshi.pdf
実際、これまでに経験したことのない暑さだったことは間違いないのですが、気温の変化をよりわかりすく示すヒートマップというものがあるようです
これはわかりやすい!ということで、150連続実験データでもこの表現手法を使ってヒートマップを作成してみたいと思います。
データの切り出し
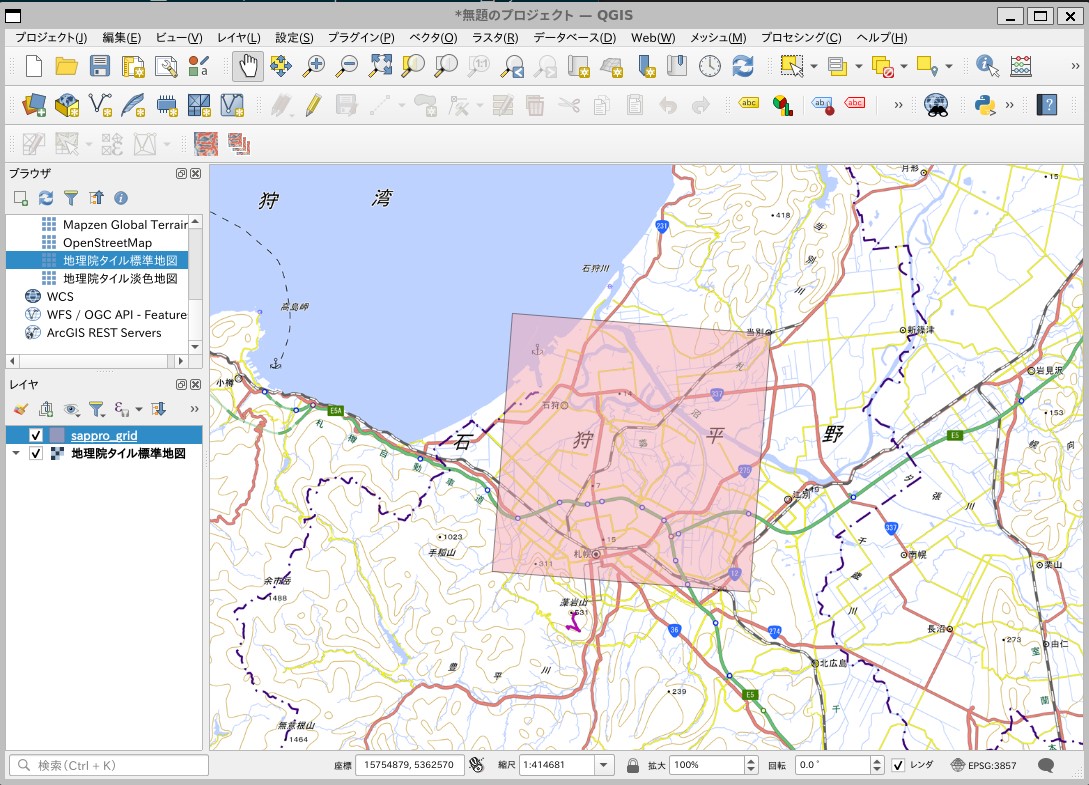
ここでは1例として札幌管区気象台に最も近い格子点における8月の平均気温のヒートマップを作成します。
地理座標は北緯43度3.6分、東経141度19.7分ですので、対応する格子点の位置を特定します。
https://www.jma.go.jp/jma/kishou/know/amedas/ame_master.pdf
# ライブラリをインポート import os import numpy as np import pandas as pd import geopandas as gpd from shapely.geometry import Polygon os.chdir("/mnt/c/Users/hoge/ONEFIFTY") # 札幌管区気象台の緯度経度 src_lat = 43 + 3.6/60 src_lon = 141 + 19.7/60 # 日本域20㎞150年連続実験データの投影法での座標を計算 wgs_SRS = osr.SpatialReference() wgs_SRS.ImportFromEPSG(4326) lcc_SRS = osr.SpatialReference() lcc_SRS.ImportFromProj4( "+proj=lcc +lat_1=30.0 +lat_2=60.0 +lon_0=135. +lat_0=0 +x_0=0 +y_0=0 +a=6371000 +b=6371000 +units=m +no_defs") trans = osr.CoordinateTransformation(wgs_SRS,lcc_SRS) out_x,out_y,z = trans.TransformPoint(src_lat,src_lon) #最も近い格子点の行番号、列番号を特定する x_vec = (-1930000.1287495417 + 10000) + np.arange(0,191) * 20000 y_vec = ((5833346.794147097 - 10000) - np.arange(0,155) * 20000)[::-1] x_ind = np.argmin(np.abs(x_vec - out_x)) y_ind = np.argmin(np.abs(y_vec - out_y)) # 確認のためのベクタを作成する x = x_vec[x_ind] y = y_vec[y_ind] df = pd.DataFrame(["Sapporo"]) df.columns=["name"] gm = [Polygon([(x-10000,y-10000),(x-10000,y+10000),(x+10000,y+10000),(x+10000,y-10000),(x-10000,y-10000)])] sapporo_gdf = gpd.GeoDataFrame(df,geometry=gm,crs=lcc_SRS.ExportToWkt()) sapporo_gdf.to_crs("EPSG:4326").to_file("sappro_grid.fgb", driver="FlatGeobuf") print(x_ind,y_ind) # 121 121
格子点を中心とした20㎞メッシュに札幌が含まれていることが確認できます。
150年連続実験データの処理
「全球及び日本域150年連続実験データ」の20km150年連続実験データから、(121,121)に位置するデータを切り出し、地上気温の日平均値を計算します。
# ライブラリをインポート import os import pathlib import numpy as np import pandas as pd import xarray as xr import rioxarray # 処理するファイルの一覧を作成する os.chdir("/mnt/c/Users/hoge/ONEFIFTY") griblist_df = pd.DataFrame({"grib_path":list(pathlib.Path("./").glob("**/*.grib"))}) griblist_df["grib_name"] = griblist_df["grib_path"].map(lambda x: x.name) griblist_df["year"] = griblist_df["grib_name"].str.extract(".*_(\d{4})\d{2}.grib").astype(int) griblist_df["month"] = griblist_df["grib_name"].str.extract(".*_\d{4}(\d{2}).grib").astype(int) griblist_df = griblist_df.sort_values("year").reset_index(drop=True) # 年ごとの日平均値を収納する配列を作成 TA_daily_mean_arr = np.zeros((griblist_df.shape[0],31)) # 年ごとに日平均値を計算 for h_index,h_row in griblist_df.iterrows(): ds = xr.open_dataset(h_row["grib_path"], engine="cfgrib") ds["time"] = ds["time"] - np.timedelta64(1, 'h') da = ds["t"][:,121,121].resample(time='1D').mean() TA_daily_mean_arr[h_index,:] = da.data np.save("TA_daily_mean.npy",TA_daily_mean_arr)
ヒートマップの作成
plotlyでヒートマップを描きます。
# ライブラリをインポート import os import numpy as np import plotly.express as px import matplotlib.cm as cm os.chdir("/mnt/c/Users/hoge/ONEFIFTY") # データをロード TA_daily_mean_arr = np.load("TA_daily_mean.npy") # 平年値(統計期間1991~2020年)を計算 TA_normal = TA_daily_mean_arr[40:70,:].mean() # ヒートマップの描画 fig = px.imshow(TA_daily_mean_arr, aspect="auto",width=550,height=800, color_continuous_scale='RdBu_r', color_continuous_midpoint=TA_normal) # レイアウト編集 fig.update_layout( title=dict(text="札幌周辺の8月の日平均気温シミュレーション(1951~2099)", y=0.98), margin=dict(t=40, b=45, l=25, r=120) ) #脚注1を作成 fig.add_annotation( font_size=10, font_family="sans-serif", x=1.04, y=0.83, xref="paper", yref="paper", xanchor="left", yanchor="top", borderwidth=1, bordercolor='black', align="left", text="「日本域150年連続<br>実験」による、札幌<br>に最も近い格子点に<br> おける1951年から<br>2099年までの8月の<br>日平均気温シミュレ<br> ーション結果。縦軸<br>が '年' , 横軸が '月日' 。<br>8月の日平均気温の<br> 平年値(1991~2020<br>年)を白とし、高温<br>を赤、低温を青とし<br> た色分けにより気温<br>の違いを表現した。<br>結果は特定の日の「<br> 気象」の状態(何月<br>何日に気温は何度か)<br>を予測しているもの<br> ではないことに注意!" ) # 脚注2を作成 fig.add_annotation( font_size=10, font_family="sans-serif", x=1.03, y=0.12, xref="paper", yref="paper", xanchor="left", yanchor="top", align="left", showarrow=False, text="本ヒートマップは、<br>文部科学省「統合<br>的気候モデル高度<br> 化研究プログラム」<br>において、地球シ<br>ミュレータを用い<br> て作成されたデー<br>タを使用させてい<br>ただいています。" ) # y軸を設定 fig.update_yaxes( tickvals=[0,9,19,29,39,49,59,69,79,89,99,109,119,129,139,148], ticktext=["1951","1960","1970","1980","1990","2000","2010","2020","2030","2040","2050","2060","2070","2080","2090","2099"] ) # x軸を設定 fig.update_xaxes( tickvals=[0,4,9,14,19,24,29], ticktext=["08/01","08/05","08/10","08/15","08/20","08/25","08/30"], tickangle=-50 ) # カラーバーを設定 fig.update_coloraxes( colorbar_len=0.4, colorbar_y=0.32, colorbar_yanchor="middle", colorbar_ticklabeloverflow="allow", colorbar_tickvals=[284,310], colorbar_ticktext=["low","high"], colorbar_title="日平均気温", colorbar_title_side="top" ) # ロゴを描画 fig.add_layout_image( sizex=0.2,sizey=0.2, source="https://pbs.twimg.com/profile_images/1664190624701222912/8gaaJj-l_400x400.png", xref="paper", yref="paper", x=1.05, y=0.995) fig.show()
ヒートマップができました。
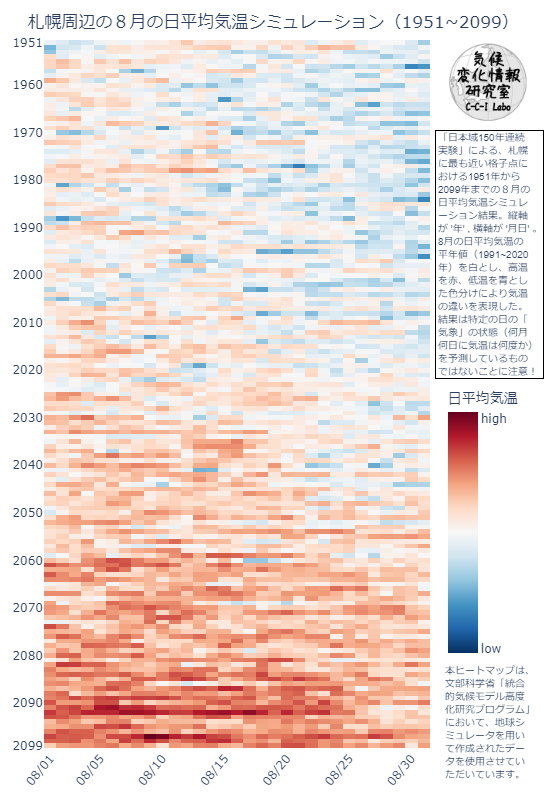
皆さんのお住まいの地域でも同様のヒートマップを作成することができます。
「全球及び日本域150年連続実験データ」の日本域20km150年連続実験データの日平均気温をヒートマップで表現する方法を紹介しました。試してみてくださいね~。
※本記事では文部科学省「統合的気候モデル高度化研究プログラム」において、地球シミュレータを用いて作成されたデータを使用しました。